
Model evaluation for the prediction of solubility of active pharmaceutical ingredients(APIs)to guide solid–liquid separator design
2018-05-17 06:35:34KuveneshnMoodleyrgenRreybDereshRmjugernth
Kuveneshn Moodley*,Jürgen Rreyb,Deresh Rmjugernth
aThermodynamics Research Unit,School of Engineering,University of KwaZulu-Natal,Howard College Campus,Durban 4041,South Africa
bIndustrial Chemistry,Carl von Ossietzky University Oldenburg,Oldenburg 26111,Germany
1.Introduction
The separation and puri fication of pharmaceutical products,or intermediates,are arguably the most important and cost intensive process steps in the pharmaceutical industry.The method,degree and efficiency of the process are generally dictated by the phase behaviour of the solute.Kolárˇet al.[1]state that over 30%of the efforts of industrial property modellers and experimentalists deal with solvent selection.It is therefore imperative that appropriate solvents are analytically selected,based on broadly-sourced information that may include phase equilibrium experimental data,reliable predictions,experience and solute theory(e.g.structure,bonds and physical properties).
Often it is not possible to determine the phase behaviour of these systems experimentally,as small amounts of each pharmaceutical product are manufactured in the initial stages of design and synthesis.Due to this constraint,many thermodynamic models have been applied to predict the solubility via predictive Gibbs excess energy models.These models include functional group approaches such as UNIFAC[2],modified UNIFAC(Dortmund)[3],and surface segment approach models,such as COSMO-RS(OL)[4],COSMO-SAC[5]and NRTL-SAC[6]and have exhibited varying degrees of success in predicting the solubility of common pharmaceutical compounds with relatively simple molecular structures[6–10].Gmehling et al.[7]and Gracin et al.[8]have explored the ability of the UNIFAC model to predict solid–liquid equilibria.Gmehling et al.[7]considered relatively simple ring structured solutes such as naphthalene and anthracene.The authors could provide good estimates by UNIFAC predictions for the systems considered.Gracin et al.[8]used the UNIFAC model to predict solubilities of single-ring pharmaceuticals such as ibuprofen and aspirin.The authors concluded that accurate predictions were not achievable,and suggested the use of the UNIFAC model for initial estimates only.
Hahnenkamp et al.[11]have evaluated and compared the predictive capabilities of the models of Fredenslund et al.,Weidlich and Gmehling,Grensemann and Gmehling,and Lin and Sandler[2–5]for systems containing ibuprofen and aspirin.The authors determined that the predictions of the model presented in Weidlich and Gmehling[3]provided the lowest deviations from the experimental data,when compared to the models from Fredenslund et al.[2]and Grensemann and Gmehling[4].Diedrichs and Gmehling[12]conducted a detailed model comparison,but only systems with alcohol,alkane,or water as a solvent,were considered.Furthermore,systems with solute mole fractions greater than 0.1 were excluded in the comparison.Schr?der et al.[13]explored the prediction of aqueous solubilities of various solid carboxylic acids that are used in the pharmaceutical industry.
Little work on the abilities of predictive models for the solubility of complex pharmaceuticals,such as polycyclic aromatics,specifically steroidal triterpenes,is available in the literature.This is mainly due to a lack of experimental data which is imperative to generate model-specific parameters that are usually essential for the application of most predictive models.It is however important that accurate predictions can be made without an extensive set of experimental data,as this would obviously limit the practicality of the predictive model.Abildskov et al.[14]have provided some satisfactory predictions for a limited set of steroidal molecules by conducting sensitivity tests on UNIFAC model parameters however this data is incomplete and not readily available.
In this work,the various aforementioned predictive models were tested to determine the most accurate method for solubility modelling for the solutes considered.The models were chosen based on the variations in the approach to solubility modelling(functional group based,segment based,reference solvent based).The differences in combinatorial and residual expressions are distinguished.The results of the predictions are intended to provide qualitative estimates of solubility data as the predictive models generally yield poor quantitative results in the case of solid–liquid equilibria.The performance of the models is correlated with the molecular surface area,molecular weight,and functional group diversity.In this work,functional group definitions based on the work of Fredenslund et al.[2]were used.
In addition,the works of Mishra and Yalkowsky[15]and Neau et al.[16]are explored for complex steroidal systems in benzene,or water,as hydrophobic and hydrophilic reference solvents.This is to determine the effect,of the assumption of zero or non-zero-approximates/experimental data,on changes in heat capacity upon fusion in systems exhibiting ideal solubility in the solid phase.Neau et al.[16]showed that the assumption of negligible heat capacity changes can cause large errors in calculated solubility,during modelling for solutes of melting points exceeding 420 K.However,an ideal liquid phase was assumed in their work.Hence,the effect of the activity coefficient was not considered.The tests of Neau et al.[16]have been limited to solute melting points of 470 K,where the different assumptions for changes in heat capacity can result in deviations from experimental data of up to 27%.The effect of the increasing difference between the experimental solubility temperature and fusion temperature is tested in this work.
The range of solute melting points considered in the test set here exceeds 520 K,with molecular weights in the range of 90–442 g/mol.It is also useful to establish differences(if any)in performance due to the solvent involved(non-polar organic vs.aqueous).The effect of the various methods of dealing with changes in heat capacity,between the solid and liquid soluteon the predicted solubility,are explored,in conjunction with the different predictive models for the activity coefficient,from the literature.This is to determine the most suitable combination of combinatorial and residual activity coefficient model terms,along with the most suitable model equation for solubility prediction.
2.Theory
The activity coefficient is a measure of the non-ideality of solutions[12].The parameter is a strong function of composition,and of temperature to a degree,but is weakly dependent on pressure,at low to moderate pressures.In some cases,the activity coefficient is greater than 1,however,values below 1 are common in solvating systems(as shown in Gmehling et al.[7]),such as solutions of phenol and alkanols or alkanes and polymers.Usually,the degree of dissimilarity between component sizes comprising a mixture is proportional to the differences in activity coefficients of those components[6].
2.1.Solid–liquid phase equilibrium
At solid–liquid phase equilibrium,the solvent is saturated with the solute.In the case of eutectic mixtures,the solubility of the solvent in the solid solute is neglected,and the chemical potential of the solute,i,in the pure solid phaseis equal to the chemical potential of the solute in the liquid solution,as shown by Bouillot et al.[10]:

The chemical potential of the solute in the liquid solution can be expressed as:

where,,is the chemical potential of the hypothetical pure liquid solute at system temperature(reference state),Tis the tempearture in Kelvin,Ris the universal gas constant in J/mol·K andis the activity coefficient of the solute in the saturated solution.

At constant temperature and pressure,the chemical potential is equal to the partial molar Gibbs energy,so that:

And hence

whereis the hypothetical partial molar Gibbs energy of melting at the system temperature and pressure[10],which is zero for the pure solute at its melting point.Assuming a constant difference in heat capacity,between the solid and the subcooled liquid solute,between the triple point and the system temperature,the following expression can be derived:
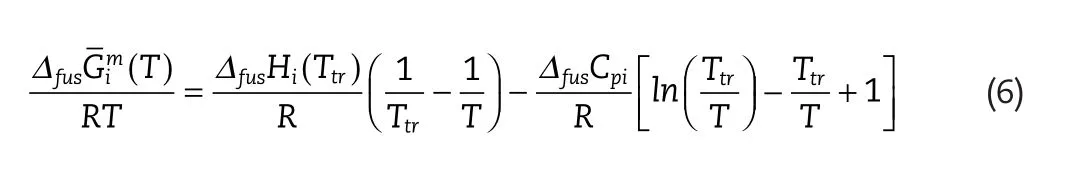
whereis the enthalpy of fusion at the triple point,Ttris the triple point temperature in Kelvin,andΔfusCpiis the difference in heat capacity between the subcooled liquid solute and the solid.
This derivation disregards the pressure influence on solid solubility,as the difference between system pressure,and triple point pressure,is regarded as sufficiently small,so that a Poynting correction term is not required.Hence the triple point at 1 atmosphere(fusTi)is often used as a substitute,due mainly to the greater abundance of this data.
Often the effect ofΔfusCpiis assumed to be small in comparison to the other term,and is omitted.This assumtion is only valid when the SLE temperature is similar to the triple point temperature.
Equation(6)then reduces to:
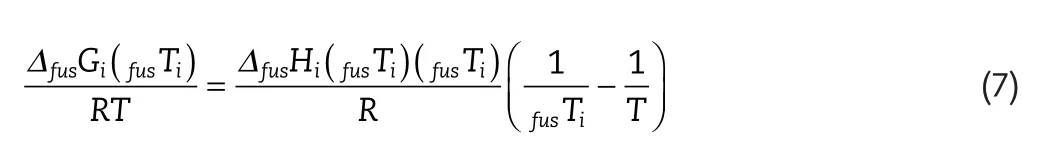
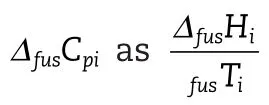
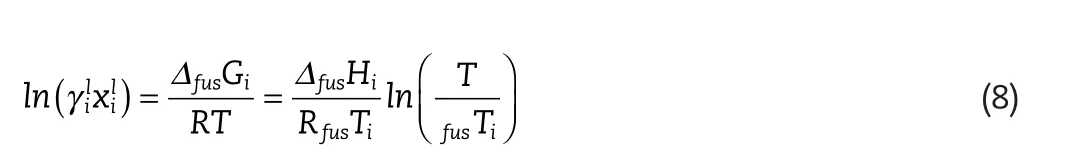
This improvement has been supported by Neau et al.[16],and is explored further in this work.
2.2.Predictive activity coefficient models
A brief description of the predictive activity coefficient models used follows.The reader is referred to the original publications for an in-depth discussion[2–6].
2.2.1.The UNIFAC and modified UNIFAC(Dortmund)model
The UNIFAC activity coefficient model,introduced by Fredenslund et al.[2],makes two contributions to the activity coefficient.Namely a combinatorial(accounting for size shape interactions),and residual(acounting for energetic interactions),component.

where,,and,,are the combinatorial,and residual contributions,respectively,and are given by the following expressions:
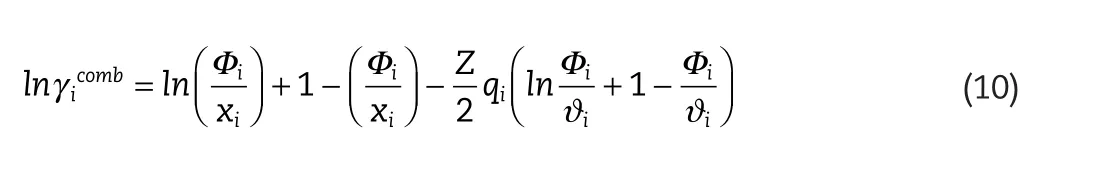
where

and

where,ri,and,qi,are the molecular volume and surface area,and Z is the coordination number.For the original UNIFAC model,the molecular volume and surface area are estimated from the group contribution values of ref.[19].
The residual term,is evaluated from group contributions:

whereis the number of functional groups of the type,k,
kin a molecule of component,i,andis the residual contribution to the activity coefficient by the functional group,k,in the pure fluid,i.Since the pure fluid,i,is also a mixture of groups,the term,is incorporated to reduce the residual term of the pure fluid to zero.
The contribution to the residual portion of the activity by the functional group,k,is given by the following relationship:
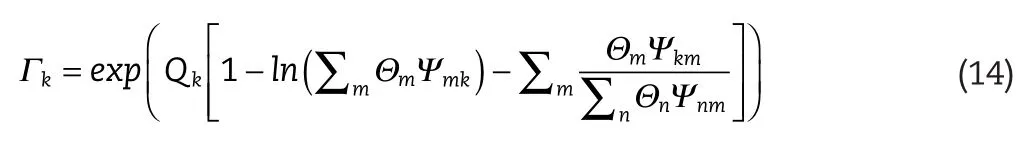
whereΘmis the surface area fraction of the functional group,m,in the mixture.The binary interaction parameter is between groups,mandn,whileamnis accounted for through the parameter,Ψmn,where:

Tis the system temperature in Kelvin.
As mentioned above,the expression forΓk,presented in Equation(14),includes the functional group,k,contributions to activity,of both the mixture and the pure fluid.
Several modifications to the original UNIFAC model have been proposed,with the most significant modifications made to the expression for the temperature dependence of binary interaction parameters,and the introduction of different combinatorial expressions,with unique group volume and area parameters,as well as component group fragmentations.
In the modified UNIFAC(Dortmund)[3]a quadratic temperature dependence of the binary interaction parameter,amn,is proposed:

Additionally,the combinatorial expression is given by:
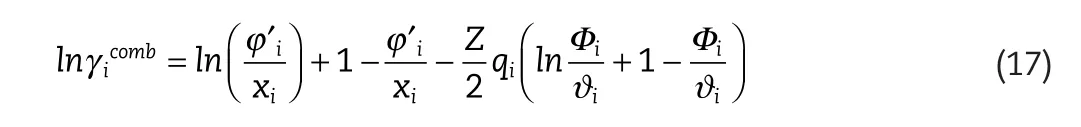
where

The parameters ofrandqare determined by data fitting,and not from the method of Bondi(1964).
The modified UNIFAC(Dortmund)model was adapted further,for application to pharmaceutical systems,by Diedrichs and Gmehling[12].This model was termed Pharma Modified UNIFAC.It was assumed,in that work,that certain functional group contributions become irrelevant in solutions of pharmaceutical molecules in common solvents,if the solubility is low,and can therefore be omitted.A unique group fragmentation scheme is used in this model.Promising results for limited classes of solvents were obtained[12].The model is however limited in applicability to a solute mole fraction of less than 0.1.
2.2.2.The COSMO-RS,COSMO-SAC and COSMO-RS(OL)models
Generally,the activity coefficient of a mixture is determined through the Gibbs excess energy function.Klamt[20]proposed a means of determining the activity coefficient,using chemical potentials from surface shielding charge densities determined by quantum-mechanical calculations.The Conductorlike Screening Model for Real Solvents(COSMO-RS)was introduced,as ana prioripredictive model,and an alternative to the traditional group contribution-based models.
In COSMO-RS,molecules of a solute–solvent system are treated as a combination of molecular-shaped,cavity surface segments.The concept involves modelling the placement of a “cavity”that is a replica of a molecule of the solute,with zero charge,inside the homogeneous theoretical solvent,with a fixed dielectric constant,ε.The energy change involved in this placement represents a component of the total Gibbs energy change of solvation.The replica molecule charges are then replaced,yielding a realistic solute.The energy change associated with this is the second contributor to the Gibbs energy change of solvation.To know how charges must be replaced,each shielding charge density(σ)must be characterized by a “sigma pro file”.
COSMO-RS(OL)is the in-built Dortmund Data Bank-modified version of the COSMO-RS model.The most significant modification to the model,in this version,includes an empirical correction term for hydrogen bonding,which is suggested to be over-compensated for in non-hydrogen bonding mixtures,in the original COSMO-RS model.The specifics of this modification are outlined in the original publication[4].
Lin and Sandler[5]have proposed some modifications to the original COSMO-RS model.The authors have stated that the expression for the chemical potential,given by ref.[20],does not converge with certain boundary conditions,and that the expression for the activity coefficient presented,does not satisfy certain thermodynamic consistency tests.
The modifications of Lin and Sandler[5]result in the Conductor-like Screening Model-Segment Activity Coefficient model(COSMO-SAC),which is reviewed here.
The derivation of the expression of the activity coefficient using the COSMO-SAC model is extensive and beyond the scope of this work,but the reader is referred to the original publications for both the COSMO-RS[4,20]and COSMO-SAC[5]models for further details.The final expression for the activity coefficient of solute,i,in solvent S,lnγi S,using the COSMOSAC model is given by:
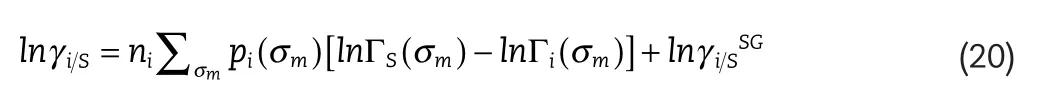
whereni,is the total number of segments contributed by molecule,i.σm,is the surface charge density of segment,m,and,pi(σm),is the frequency of surface charge density,m,of component,i,given by:

whereni(σm),is the total number of segments in component,i,with charge density,is the segment activity coefficient in the mixture for segments with charge density,σm,given by:
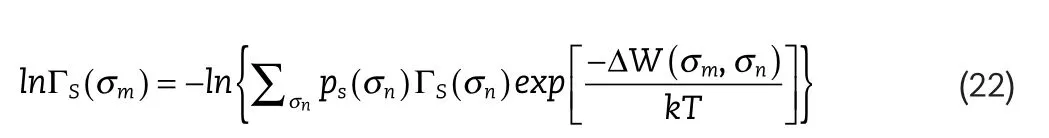
where ΔW,is the exchange energy andk,is the Boltzmann constant.,is the segment activity coefficient in the pure component,i,for segments with charge density,is the Staverman–Guggenheim[21,22]combinatorial term given by:
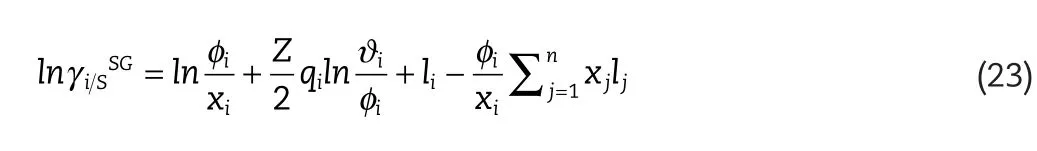
whereis the surface area fraction given by:

whereis the volume fraction parameter given by:

and

2.2.3.Non-random two liquid segment activity coefficient model(NRTL-SAC)
The NRTL-SAC[6,23]model,is based on the polymer NRTL model by Chen[24],and was developed specifically for the use in the modelling of the activity of complex molecules,such as pharmaceuticals.The non-ideality is accounted for based on“contributions”from four different conceptual segments that make up a particular component.These include polar-positive,polar-negative,hydrophobic and hydrophilic segments.Each molecular surface is conceptually divided into these segments,in different proportions of the molecular surface area.Every molecule is thus designated a conceptual segment surface“composition”.The surface interactions between pairs of segments are accounted for through constant binary interaction parameters only.
The main differences between the original NRTL model of Renon and Prausnitz[25],and the NRTL-SAC model,include the concept of segment interaction,and the addition of a combinatorial term,as size/shape interactions become considerable in larger complex molecules.Additionally,the NRTL-SAC model has no in-built temperature dependency.
The combinatorial term of Flory–Huggins[26,27],is used in the model.The subscripts,AandB,are used to denote pure components,whereas the subscripts,i,j,k,m,and,m′,are used to represent segment-based species indices.

where

whererA,is the total number of segments,i,in component,A,and,φA,is the segment mole fraction of component,A.
The residual term is identical to that of the polymer NRTL[24]where:
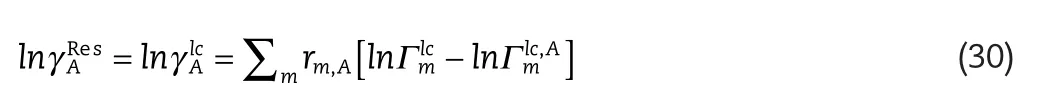
whereis the segment activity coefficient of species,m,in the mixture,and,is the segment activity coefficient of species,m,in the pure component,A,and these are calculated from the following relations:
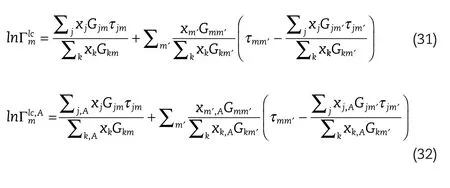
where and


whererm,A,is the number of each segment of type,m,in component,A.xj,is the segment mole fraction of segment,is the mole fraction of component,and,α,are the regular NRTL parameters,withτjmbeing the binary interaction energy parameter between segment,jandm.
3.Experimental solubility and pure component property data
3.1.Pure component thermodynamic data
Pure component property data(melting temperature,enthalpy of fusion and heat capacity),of the active pharmaceutical ingredients selected for modelling in this work is limited in the literature.Bouillot et al[10]state thatthermodynamic properties of the solids are scarcely accurate,when referring to experimentally determined heat of fusion and melting temperature data of pharmaceutical products.Bouillot et al[10]have proposed using average values of the available physical property data.
In this work,the pure component data was used,where available,for the calculation of the activity coefficient from solubility measurements.However,in the case of mestanolone,the enthalpy of fusion was predicted by the method of Chickos and Acree[28].The pure component properties from the literature,are presented in Table 1,along with molecular masses,van der Waals molecular surface area,and functional group diversity.Since the fragmentation of each molecule into its different functional groups was done in the same way as the original UNIFAC model,the functional group diversity represents the number of unique original UNIFAC functional groups in a molecule.
A principal component analysis was conducted on the test set using the solute solubility in an alcohol/non-polar solvent,and in water,temperature of fusion,enthalpy of fusion,and molecular mass,as input descriptors.The sample set of components selected were found to be heterogeneous,with a minimum of 80%of the datasets described by all combinations of input descriptors.
3.2.API selection and experimental solubility data
Solubility data for the APIs selected here(specifically steroids and triterpenes),are extremely limited in the literature.It is therefore important that preliminary predictions of the solubility of these solutes can be made in order to provide,at the very least,initial estimates for later use in the design and optimization of separation processes such as crystallization.
While all components contain a similar basic structure,they differ according to the number of ester,ketone and alcohol groups in the molecule which should be the major cause of the dependence of the solubilities on the solvent.The major differences in solubility between the solutes are due to the differences in melting temperature,and heat of fusion.
The components,and literature sources[29,35,39,47–62],for the experimental solubility data,are presented in Table S1 in Appendix A.
4.Results and discussion
In order to quantify the quality of the predictions for the various models tested,a Percentage Deviation(PD)was de fined:

whereis the calculated and experimental solute compositions,andN,is the total number of data points considered.is the average experimental composition for a particular set.
4.1.Assumptions regarding the heat capacity change of fusion
As menioned above,the availability of the physical property data for the solutes considered is limited.The standard state used in the calculation of these properties is a pure hypothetical liquid at a temperature much lower than the actual melting point.In order to calculate the change of heat of fusion with temperature,the difference of the heat capacities of the solid and the subcooled liquid is required(given by Equation(6)).This calculation is often simplified by assuming a negligible heat capacity difference in this range(given by Equation(7)).An alternative assumption is to approximate the heat capacity change as the entropy of fusion(given by Equation(8)).Uncertainties can thus be introduced in the calculation of the activity coefficient,from solubility data,and vice versa.
The effect of these two assumptions is considered in this work,using benzene as a reference solvent.These results are compared in Table 2.Mishra and Yalkowsky[15]have analysed this behaviour for similar solutes,in benzene.In their work,for APIs in benzene,employing the UNIFAC combinitorial term,with the Scatchard–Hildebrand[63,64]residual term,with the assumption of zero heat capacity changes,provided the best prediction of solubility.Benzene is used as a representative solvent for all hydrophobic solvents(alkane,aliphatics,alkenes,alkynes)due to the abundance of experimental data available in the literature for pharmaceutical systems with benzene as the solvent.It is not recommended as a pharmaceutical process solvent as it is a class one residual solvent.In practice,less hazardous hydrophobic solvents such as alkanes are used.Unfortunately,the data for pharmaceutical+alkane systems for a specific alkane e.g.hexane was not abundant in the literature and so a comprehensive result regarding heat capacity assumptions would not have been possible.It is assumed that the results obtained in this work using benzene would be very similar for systems composed of other hydrophobic solvents.
All three assumptions regarding the heat capacity change of fusion(ΔfusCpi),at solid–liquid equilibrium,were explored here.These included treatingor usingan experimental,or empirically-predicted value forΔfusCpi.The mean percentage deviations between experimental data,and the model predictions,are presented in Table S1.The results of overall performance are presented in Table 2,along with the activity coefficient model details used for the predictions.
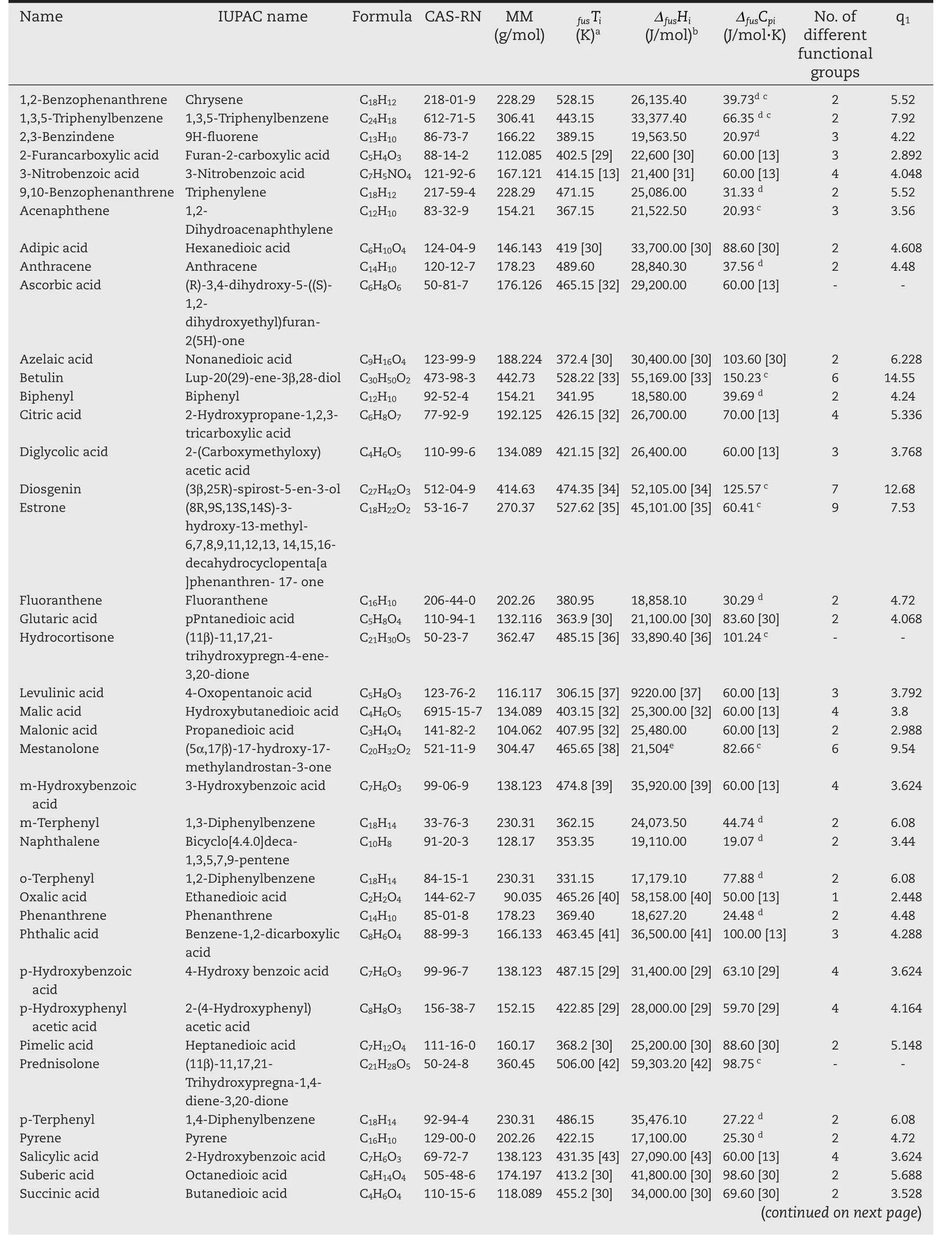
Table 1–Physical properties of the solutes used in this study.
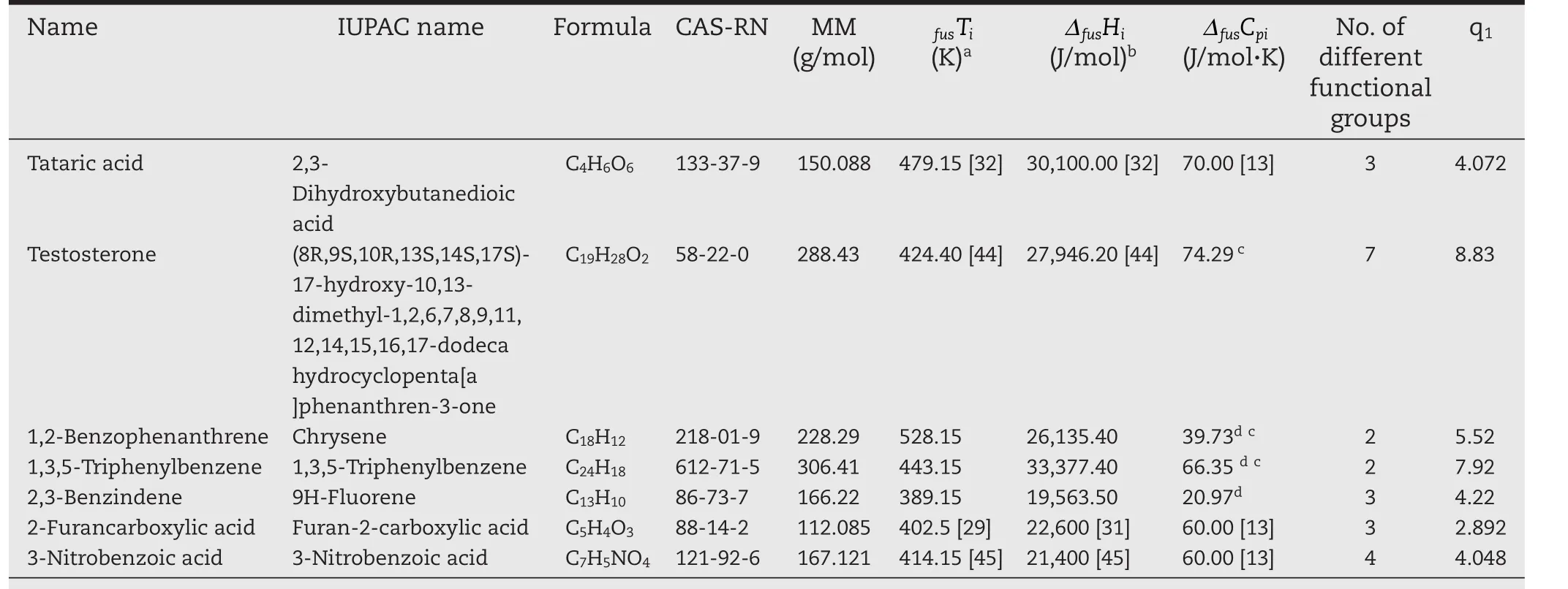
Table 1–(continued)
The effect of the activity coefficient model performance can be eliminated by only comparing eachΔfusCpiassumption case,on a model by model basis.In the case of the lower molecular mass APIs,hydrophobic and hydrophilic solutes were treated separately,as virtually immiscible solute–solvent systems gen-erally do not provide consistent trends with regards to prediction.Furthermore,the quality of experimental data for such systems is usually poor.Triterpenes were all treated simultaneously as these APIs are neither strictly hydrophobic nor hydrophilic.A limited set ofΔfusCpidata was found in the literature.In some instances,it was possible to calculateΔfusCpifrom experimental pure component solid and liquid heat capacity data,where available in the literature.
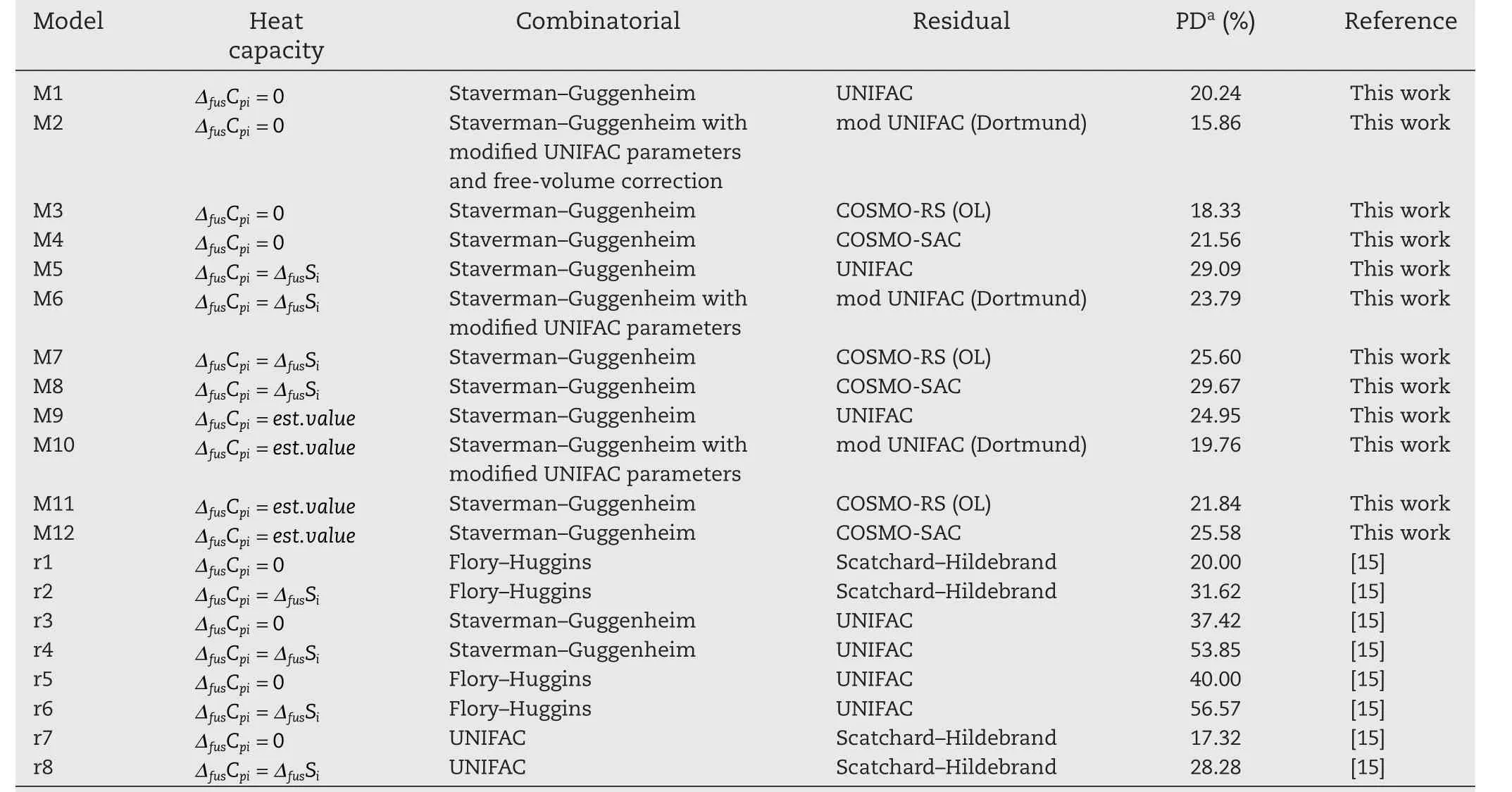
Table 2–Mean Percentage Deviations of various solutes in benzene.
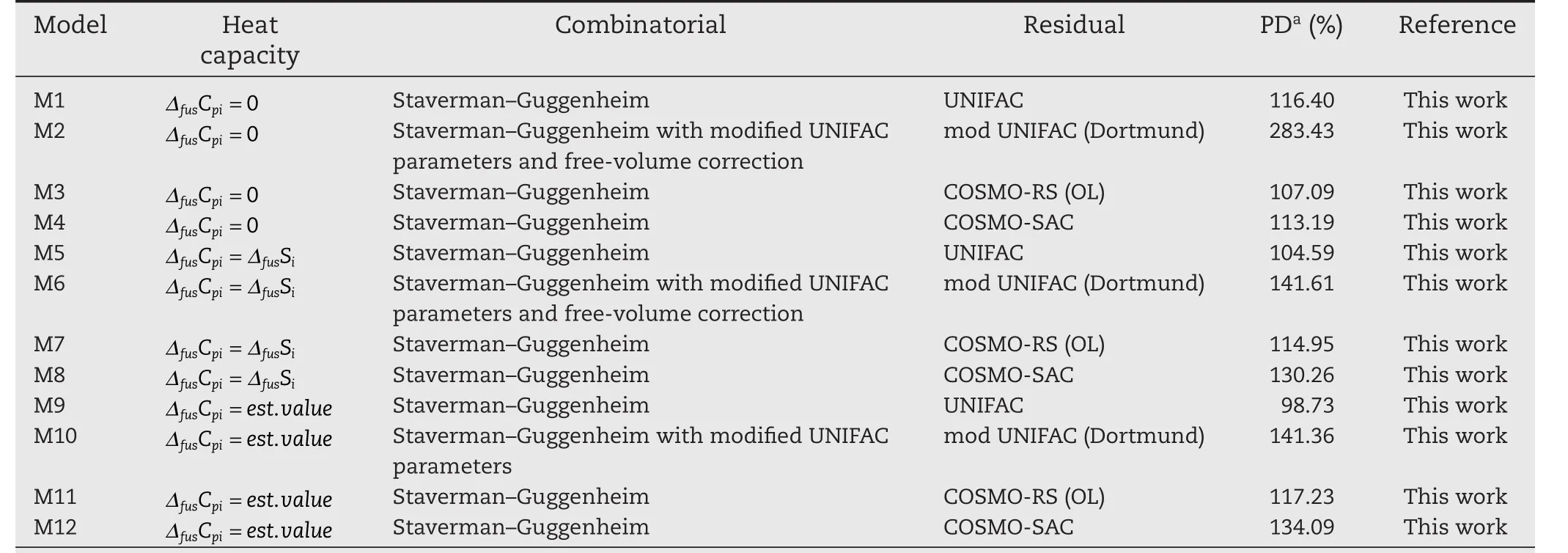
Table 3–Mean Percentage Deviations of various solutes in water.
To predictΔfusCpifor those systems,for which no experimental data was available,an empirical correlation was developed by correlating the availableΔfusCpidata with solute molecular masses and van der Waals surface areas.For nonoxygen containing solutes the following relation was determined:
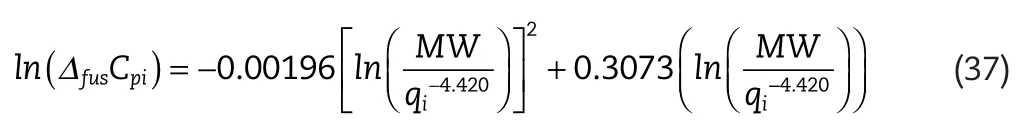
and for oxygenated solutes:
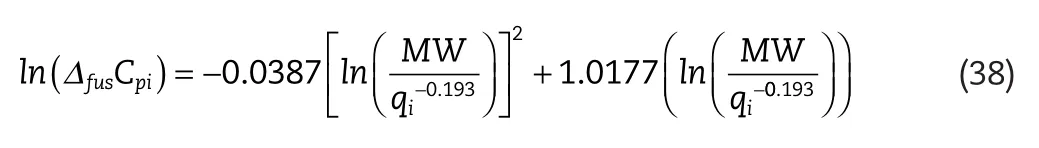
whereΔfusCpiis the heat capacity change of fusion,MWis the component molecular mass(g/mol)andqiis the molecular surface area.
Since the above equations have no theoretical basis they are only recommended for estimates in the absence of any experimental data of the solute being considered.The empirical model parameters were determined by least squares regression using the following objective function:

where the superscriptsexpandcalcrefer to the experimental and calculatedΔfusCpivalues respectively,andnis the total number of experimentalΔfusCpipoints considered.The uncertainty in the calculatedΔfusCpiis estimated to be 20%–25%.
The sources of the pure component properties used are indicated in Table 1.For the systems comprised of benzene as a solvent,the results determined here correspond with the results in ref.[15].Namely,the assumption of negligibleΔfusCpiseemingly provides the closest replication of the experimental data.This finding may be due to poor estimates ofΔfusCpi.For the systems where water is used as the solvent(summarized in Table 3),the assumption of an estimatedΔfusCpivalue provides the lowest replication of experimental data.It is therefore clear that ideal solubility assumptions are not suitable when comparing the performances of Equations(6–8)).
4.2.Selecting a suitable predictive activity coefficient model
Essentially,all predictive models require certain information about the solute in order to be utilized.For the UNIFAC-based models group,volume and surface,as well as group interaction parameters,represent the functional groups,and their energetic interactions.The COSMO-based models require so-called sigma pro files,that characterize the shielding charge distribution,as well as the cavity volume and surface.
In this work the Oldenburg version of COSMO-RS[20](COSMO-RS(OL)[4])was used.Unfortunately group interaction parameters and segment area parameters were not available for all groups of solutes and solvents considered for prediction.Hence,not all solubilities could be described by all of the predictive methods.These systems are indicated by a dash in Table S1.The sigma pro files of the solutes,used in the COSMO-RS(OL)and COSMO-SAC methods,were determined by Gaussian 03 calculations with the hybrid density function theory type B3LYP,and basis sets 6-311G(d,p)[65].These profiles were obtained from the Dortmund Data Bank software package(2012)[46].
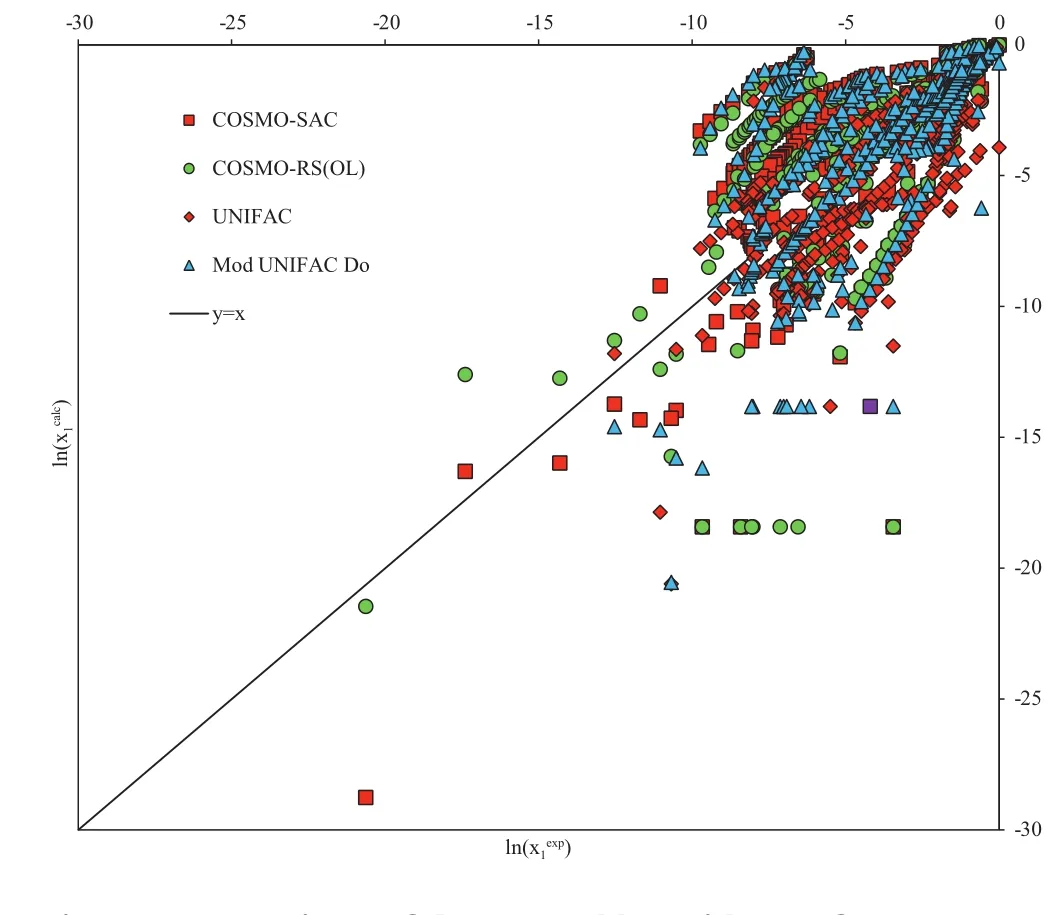
Fig.1–Comparison of the natural logarithms ofexperimental and model calculated solubility composition(x1).
The mean percentage deviations between experimental data and the model predictions are presented in Table S1.These results are presented graphically in Fig.1 for ease of comparison.In a few cases,the SLE calculation failed to converge with a composition,and these are indicated in Table S1.
In the majority of the systems tested,all the predictive models tend to underestimate the solubility.Furthermore,very large discrepancies are apparent for sparingly soluble solute–solvent mixtures,such as the triterpines.In Table 4,however,it is shown that the original UNIFAC model with the Staverman–Guggenheim combinatorial term provides a superior replication of the experimental solubility and in some cases,is almost twice as precise.It must be noted,however,that the UNIFAC model cannot be applied to the systems composed of prednisolone and hydrocortisone,as these molecules cannot be fragmented by UNIFAC.
For systems with benzene as a solvent,the modified UNIFAC(Dortmund)model,with the Staverman–Guggenheim combinatorial term,and free-volume correction,is recommended;and the original UNIFAC model,with the Staverman–Guggenheim combinatorial term,is recommeneded when water is used as a solvent.
In Figs.2–4 an attempt is made to correlate the prediction capabilities of each model considered with molecular weight,van der Waals molecular surface area,and functional group diversity,in a non-polar solvent(benzene).The van der Waals molecular surface area was determined using the method of Bondi[19].It is con firmed,from the presented figures,that virtually no correlation of these parameters to solubility exists in the systems considered here.Similar results were obtained when water is used as a solvent.It must be mentioned that the PDs in Figs.2–4 are much larger than those presentedin Table 2,as the mean compsition(xexp, was calculated separately for each solute–solvent set in this case.
Table 4–Mean Percentage Deviations of triterpene/steroid solutes in various solvents.
Fig.3–Correlation of model percentage deviations with van der Waals area parameter(q1)in benzene as a solvent.
Fig.4–Correlation of model percentage deviations with number of different functional groups present in solute for benzene as a solvent.
Fig.5–Comparison of the natural logarithms ofexperimental and model calculated solubility composition(x1)with the NRTL-SAC model.
The NRTL-SAC model was applied to a subset of the dataset considered here.Comparisons are only made to experimental data,as the model is semi-correlative and would not offer a fair comparison to the purely predictive models discussed above.In order to apply the NRTL-SAC model to solubility predictions,the segment area parameters(X,Y+,Y?and Z)must be known for the solutes and solvents considered.If these parameters are not available in the literature,they can be regressed from solubility data via the calculation of the activity coefficient,and using pure component property data.Some of the NRTL-SAC model parameters for the solutes were not available in the literature,and were therefore determined by the regression of the solubility data provided in Table S1.These new parameters are available in Table 5,along with literature sources where available.
After the application of the NRTL-SAC model,solubility predictions were performed using the new segment area parameters,and solvent parameters,provided by Chen and Song[6],as shown in Fig.5.The results reveal that the NTRLSAC model generally does not exhibit any tendency to over-,or underpredict,the experimental solubility.Again,the predictive capability of the model is a qualitative representation,in most cases,of the systems of steroidal APIs that were tested.This is a significant deficiency,as the model is semi-correlative as four component specific model parameters are required for application.
Table 5–Calculated segment area parameters for NRTL-SAC.
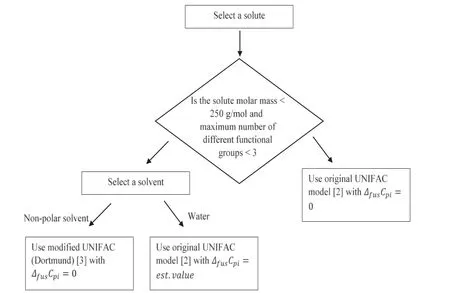
Fig.6–Decision tree for predictive model selection andΔfusCpiassumption.
In Fig.6 a decision tree is presented to assist in the selection of an appropriate model and assumption forΔfusCpidepending on the solute and solvent class.
5.Conclusion
Where model parameters were available in the literature,solubility predictions were carried out,using various predictive models,for the polycyclic steroidal and triterpene solutes considered in this work.
It was found that the modified UNIFAC(Dortmund)model provided a superior solubility prediction,when benzene as a solvent was considered.The original UNIFAC model provided a superior solubility prediction in aqueous systems.The heat capacity changes of fusion were found to be solvent dependent;and hence,ideal solubility could not be assumed.
A degree of correlation was found between molecular mass and van derWaals surface area,and heat capacity changes of fusion.Generally,the UNIFAC-based,COSMO-based models tended to underestimate the solubility in the triterpene solutes,while the NRTL-SAC model showed no appreciable under-or overestimating tendencies.However,the original UNIFAC model provided a superior solubility prediction for the triterpene/steroid systems,with no significant effect from the assumptions regarding heat capacity changes upon fusion.
New NRTL-SAC segment area parameters have been determined for some of the solutes considered in this work.This information can be used as a subsidiary guide for the selection of solvents in crystallization process design involving the studied solutes,however experimental results will be required if quantitative data is desired.
Conflicts of interest
The authors declare that there are no conflicts of interest.
Acknowledgments
This work is based upon research supported by the National Research Foundation of South Africa under the South African Research Chair Initiative of the Department of Science and Technology and the National Research Foundation Research and Innovation Support and Advancement(RISA)program.
Appendix:Supplementary material
Supplementary data to this article can be found online at doi:10.1016/j.ajps.2017.12.004.
R E F E R E N C E S
 Asian Journal of Pharmacentical Sciences2018年3期
Asian Journal of Pharmacentical Sciences2018年3期
- Asian Journal of Pharmacentical Sciences的其它文章
- LAL test and RPT for endotoxin detection of CPT-11/DSPE-mPEGnanoformulation:What if traditional methods are not applicable?
- Activity of Brucea javanica oil emulsion against gastric ulcers in rodents
- Systematically optimized topical delivery system for Loperamide hydrochloride:Formulation design,in vitro and in vivo biopharmaceutical evaluation
- Investigating the molecular dissolution process of binary solid dispersions by molecular dynamics simulations
- Preparation of glutinous rice starch/polyvinyl alcohol copolymer electrospun fibers for using as a drug delivery carrier
- Intra-articular delivery of tetramethylpyrazine microspheres with enhanced articular cavity retention for treating osteoarthritis