
Balanced Discriminative Transfer Feature Learning for Visual Domain Adaptation
2021-01-19 04:07:52SULiminZHANGQiangLIShuangChiHaroldLIU
ZTE Communications 2020年4期
SU Limin,ZHANG Qiang,LI Shuang,Chi Harold LIU
(1.Beijing Institute of Technology,Beijing 100081,China;2.ZTE Corporation,Shenzhen 518057,China)
Abstract: Transfer learning aims to transfer source models to a target domain.Leveraging the feature matching can alleviate the domain shift effectively,but this process ignores the relationship of the marginal distribution matching and the conditional distribution matching.Simultaneously,the discriminative information of both domains is also neglected,which is important for improving the performance on the target domain.In this paper,we propose a novel method called Balanced Discriminative Transfer Feature Learning for Visual Domain Adaptation (BDTFL).The proposed method can adaptively balance the relationship of both distribution matchings and capture the category discriminative information of both domains.Therefore,balanced feature matching can achieve more accurate feature matching and adaptively adjust itself to different scenes.At the same time,discriminative information is exploited to alleviate category confusion during feature matching.And with assistance of the category discriminative information captured from both domains,the source classifier can be transferred to the target domain more accurately and boost the performance of target classification.Extensive experiments show the superiority of BDTFL on popular visual cross-domain benchmarks.
Keywords:transfer learning; domain adaptation; distribution adaptation; discriminative information
1 Introduction
Labeled data are very important for supervised domain adaptation.However,it is time-consuming and expensive to annotate data manually in real application.To address this limitation,transfer learning becomes an effective alternative choice by applying the knowledge extracted from an available well-labeled source domain to a target domain.There is a common assumption in transfer learning that source data and target data belong to related but different distributions[1].This can provide a promising approach to the scenarios that suffer from a shortage of labeled data[1-5].
Most existing distribution adaptation methods achieve either domain-wise alignment,class-wise alignment or both of them.Both theoretical verification and experiment results indicate the adapting marginal distribution and conditional distribution of both domains could obtain better performance.However,domain-wise alignment and class-wise alignment are often considered as equally important.In this case,the discrepancy of these two distributions is ignored.In fact,marginal distribution matching and conditional distribution matching should be given different weights under different scenarios.Under the circumstance that the correlation between the source domain and the target domain is lower,marginal distribution needs to be more valued.When the target domain is closely similar to the source domain,conditional distribution should be given more attention.If we notice this situation and give different weights to these two domain matching,the alignment of source and target domains will be more accurate.
Achieving domain matching simultaneously brings a new problem that different categories may be wrongly matched.Therefore,we should not only achieve feature matching,but also need the learned feature to be class-discriminative.Once the feature of samples is class-discriminative,points belonging to the same class would be clustered into compact clusters and different clusters would move away from each other,which is helpful to classification of the model.
In order to solve above problems,we propose a novel method called Balanced Distribution Transfer Feature Learning(BDTFL).BDTFL can not only balance the relationship of both distribution matchings,but also encourage the learned features to be class-discriminative.On one hand,for different transfer learning tasks,BDTFL can effectively adjust relative weight of both distribution matchings.On the other hand,we also alleviate category confusion during domain-wise alignment by leveraging category discriminative information of both domains.When the learning feature appears class-discriminative,discriminative information of samples is exploited to boost the classification performance.Several existing methods can be regarded as special cases of BDTFL.To evaluate the performance of BDTFL,we conduct comprehensive experiments on several visual cross-domain classification tasks.The results verify that our method can outperform the baselines significantly.
We summarize our contributions as the following three points:
(1) We propose a novel transfer learning method BDTFL to balance the marginal and conditional distribution matching.BDTFL can adaptively adjust relationship of both distribution matching and achieve more accurate alignment.Thus,several transfer learning methods can be treated as special cases of BDTFL.
(2)Our method adopts the triplet loss to exploit the discriminative information among categories.When the learned features with discriminative information are extracted to match the marginal and conditional distributions across domains,we encourage the smaller distance between samples with the same label and the larger distance between samples with different labels,which improves classification effect of the model on the target domain.
(3) Comprehensive experiments on several visual across-domains datasets demonstrate the superiority compared with other state-of-the-art methods.
2 Related Work
The prior work has achieved a promising process in the field of domain adaptation.Existing domain adaptation methods can be roughly divided into two categories:instance reweighting and feature extraction.Our proposed method BDTFL belongs to the feature-based learning methods.Thus,we will focus on feature extraction approaches to discuss.
A transfer component analysis (TCA)[6]approach is proposed to minimize the distance between source and target domains using the maximum mean discrepancy metric[7]by searching transfer component.Furthermore,LONG et al.[8]put forward joint distribution adaptation (JDA) to jointly match marginal and conditional distributions of source domain and target domain in a principal dimension reduction procedure.Based on JDA,transfer joint matching (TJM),proposed in Ref.[9],reweights source instances to reduce difference between two domains.
To capture the discriminative information of two domains,Ref.[10] adds the supervised source class cluster to the domain matching process.Furthermore,a domain-invariant and class-discriminative (DICD) approach[11]tries to simultaneously maximize the inter-class dispersion and minimize the intraclass variance of source and target data to mitigate the domain shift.Inspired by DICD,our method explores class-discriminative information during the feature matching in the latent space.
However,the above methods ignore the relationship of two distribution matching for different scenes.They just simply and roughly add metrics together.Different from the above methods,our method can adjust the relationship of two distribution matching according to different scenes and capture class-discriminative information of two domains.
3 Proposed Approach
In this section,we first demonstrate the problem definition and then show how to learn adaptive domain-invariant feature representation with category discriminative information in our method.
3.1 Preliminary and Motivation

During the feature extraction process,we focus on the following two points:
(1) Effective feature extraction can alleviate domain shift.For different scenes,the relationship of the marginal distribution and conditional distribution should be taken into consideration.When source and target domains match in the embedding space,our method balances the relationship of the marginal distribution and conditional distribution,which is different from JDA.
(2) To further improve the performance of the model,the samples sharing the same label are expected to gather closer and clusters with different labels to be far away from each other.Therefore,we extract the category-discriminative information by minimizing the intra-class dispersion and maximizing the inter-class compactness.
3.2 Learning Adaptive Domain-Invariant Features
We are devoted to extract adaptive domain-invariant feature representation such that the source model trained by source data can always be well applied to target data in different scenarios.In this way,we search a linear domain-invariant project to discover shared subspace where the domain shift is effectively alleviated.
3.2.1 Joint Feature Matching
Since the source and target domains are related but different,it is essential to match the marginal distributions and conditional distributions across domains to achieve overlap between the source domain and target domain.The metric Maximum Mean Discrepancy is adopted to measure the distribution distance.The mean discrepancy of the marginal distributions and conditional distributions is represented as:
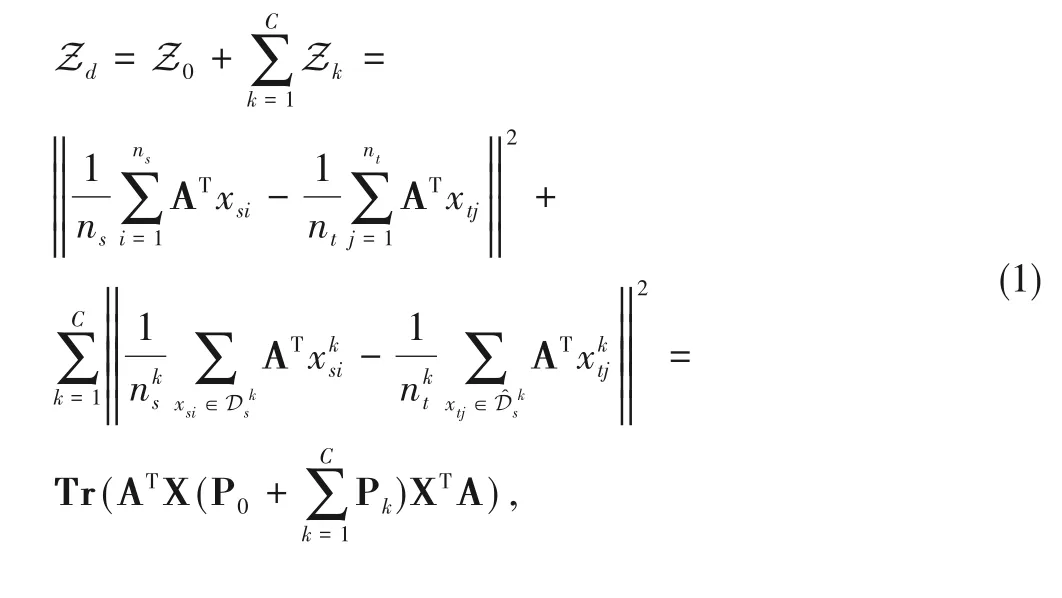
where XSand XTare concatenated by column as X.The marginal distribution distance matrix P0and the conditional distribution distance matrix Pkcan be formulated respectively as:
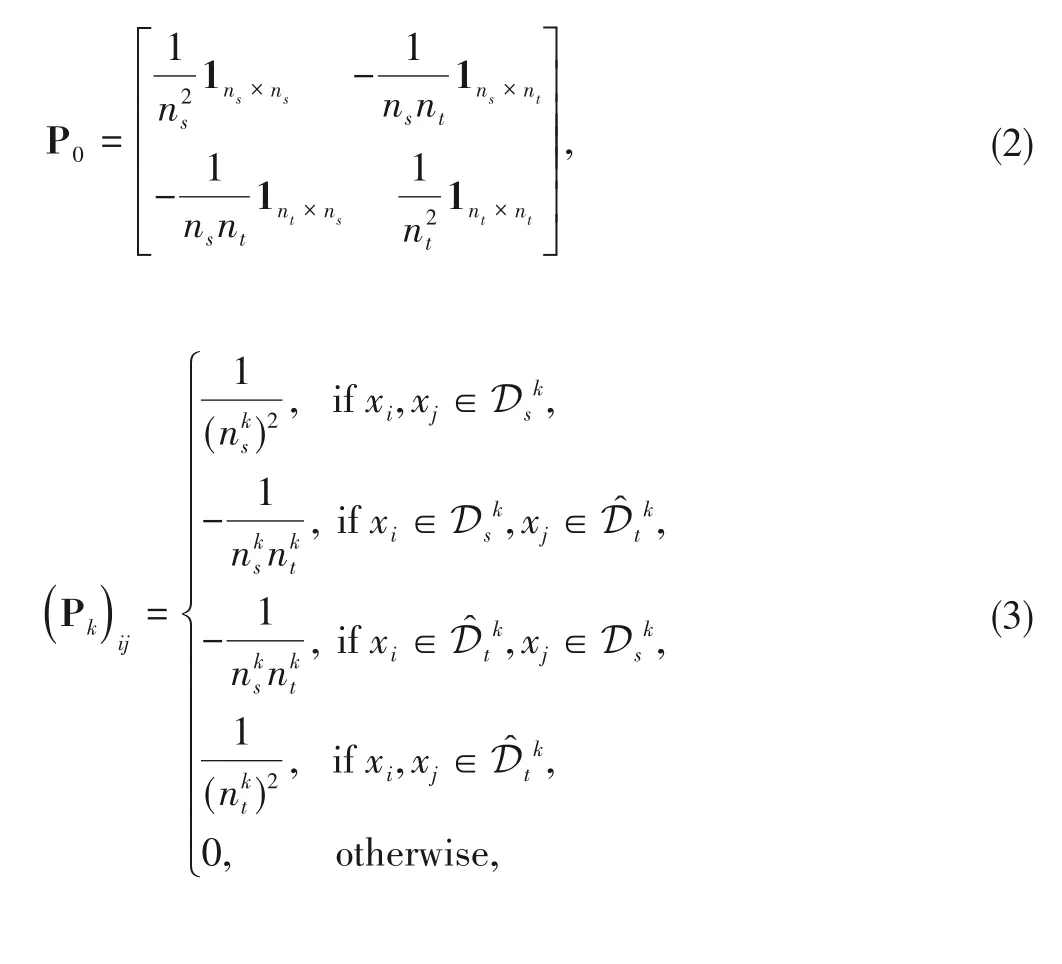
where 1m×nis defined asm×nmatrix filled with one.
We need to minimize Eq.(1)to achieve marginal and conditional distribution matching in extracted feature subspace.However,in this process,the marginal distribution and conditional distribution are equally important.In fact,their importance varies from different scenarios.The relationship between marginal distribution matching and conditional distribution matching should be balanced for different scenarios.
3.2.2 Balanced Feature Matching
BDTFL innovatively adjusts the relative magnitude of marginal distribution matching and conditional distribution matching to adapt different scenarios.Specifically,through a factorρ,we adaptively adjust the relative magnitude of marginal distribution matching and conditional distribution matching.In this way,BDTFL can satisfy different requirements of various scenarios.
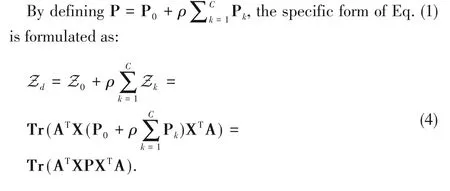
When the domain discrepancy is too large,there exists large diversity of class-wise distributions across domains.Class-wise alignment would then bring about serious class confusion.As a result,the class-wise alignment does not make any sense and even causes negative transfer problem.Thus,the class-wise alignment should be weakened in this case.However,if the target domain is closely similar to the source domain,the class-wise alignment should be enhanced.In that case,we should pay more attention to conditional distribution matching.The application scenarios can be greatly expanded by balancing marginal distribution matching and conditional distribution matching.We should estimate the similarity of the source and target domains according to different scenarios and then selectρ.In this paper,the values ofρare selected according to the performance in experiments.
3.2.3 Learning Category-Discriminative Information
Completing the above steps,we simultaneously align marginal and conditional distributions across domains to alleviate the domain shift.We also expect the learned feature representations in the latent shared subspace to be discriminative.On one hand,if samples sharing the same label are more concentrated and clusters sharing different labels are more dispersed,the source classifier can be well generalized to the target domain and achieves better performance on the target domain.On the other hand,with the assistance of the discriminative information captured from both domains,conditional distribution matching can be more accurate.
Inspired by triplet loss[11-13],we adopt the strategy that makes the samples sharing the same label close and clusters with different labels far away from each other in the extracted feature subspace.The corresponding matrix of the distance loss of source data can be formulated as:
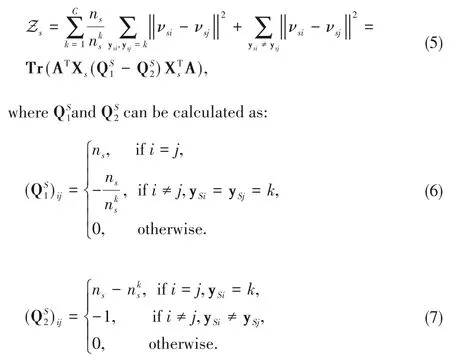
In the target domain,we utilize the pseudo label to make similar derivation and definition.We define Q1=diag(,) and Q2=diag(,),and the whole categorydiscriminative loss for both domains is obtained as:
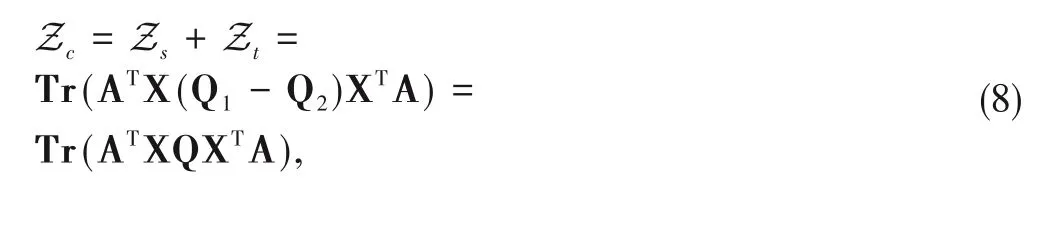
where Q=Q1-Q2.
The minimization of Eq.(8)encourages intra-class compactness and inter-class dispersion to enhance the discriminative characteristic of the learned representation.
3.2.4 Overall Framework
We incorporate Eqs.(4) and (8) into one formulation,which represents the overall loss of BDTFL.Then we minimize this overall loss as:

whereIdrepresentsanidentity matrix ofdimension dandH=represents the centering matrix.Besides,βis the regularization coefficient for avoiding overfitting.
If we incorporate the matrix forms of Eqs.(4) and (8),Eq.(9)can be rewritten as:
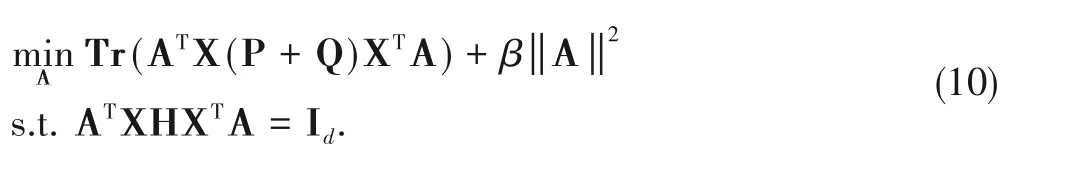
The constrained optimization problem (10) can be regarded as a generalized eigen-decomposition problem.The optimal solutionw.r.tA(A ∈Rm×d)can be solved as:
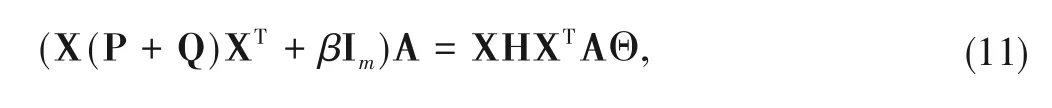
where Θ=diag(θ1,θ2,...,θd)∈Rd×dis a diagonal matrix with Lagrange Multipliers.The optimization problem (11) is also a generalized eigen-decomposition problem.And the optimal solution is the generalized eigenvectors of Eq.(11) corresponding to the d-smallest egienvalues.BDTFL can be kernelized to be applied to nonlinear scenarios.Through the above steps,we achieve the joint feature matching simultaneously retaining the discriminative information in BDTFL.
Recently,deep neural networks have been applied into transfer learning.Fine-tuning can be effectively used to transfer knowledge extracted from a source dataset to a target task.Several factors that influence the performance of fine-tuning are systematically investigated in Ref.[14],including the distribution of source and target data.In recent works on deep domain adaptation,discrepancy measures are embedded into deep architectures to reduce the gap between the source domain and target domain.Theoretically,BDTFL can be combined with the deep neural network to learn better feature representation,which will be further explored in the future.
4 Experiments
In this section,we evaluate the performance of BDTFL with massive state-of-the-art shallow domain adaptation methods on several popular visual cross-domain benchmarks.
4.1 Description of Datasets
Two widely-used benchmarks are adopted in our experiments,including Office-31(DeCAF7)[15]and CMU-PIE[16].Office-31 includes 4 652 images with 31 categories composed of three domains:Amazon (A),Webcam (W) and DSLR (D).CMU-PIE contains more than 40 000 face images from 68 individuals.
Considering different pose factors,we select 5 out of 13 poses as Ref.[8].The detail of the datasets is shown in Table 1.
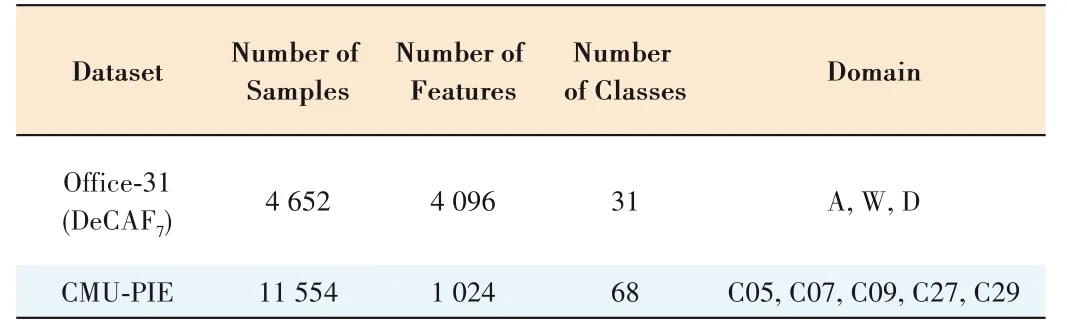
▼Table 1.Cross-domain datasets used in the experiments
4.2 Comparison Methods
We compare our method with the following seven methods:
·1-Nearst Neighbor Classifier(1NN)[17];
·Pricipal Component Analysis(PCA)[18];
·Geodesic Flow Kernel(GFK)[19];
·Transfer Component Analysis(TCA)[6];
·Joint Distribution Adaptation(JDA)[8];
·Subspace Alignment(SA)[20];
·Discriminative Transfer Subspace Learning(DTSL)[21].
Among these seven methods,the first two are traditional transfer learning methods and the others are state-of-the-art shallow transfer learning methods.
4.3 Implementation Details
1NN is acted as the final classifier,while 1NN,PCA,GFK,TCA,SA,DTSL and BDTFL are acted as feature extractors.We searchρin{0.001,0.01,...,100}for BDTFL.After the reduction of dimensionality,the feature numberdis fixed as 100.When extracting the feature,we use the linear kernel in all the experiments.The iteration numberTin the experiments is fixed as 10.The target classification accuracy is considered as the evaluation metric of the methods.
4.4 Experiment Results
The following experiment results present the superiority of the proposed method in this paper.
(1) Results on the Office-31 dataset (Table 2):On almost all the tasks,BDTFL achieves great advantage compared with the others.On A→W and W→A tasks,our method obtains a significant performance improvement of 7.66% and 5.19%compared to the best baseline SA.The target average classification accuracy of our method reaches 70.47%,2.57% more than the best baseline.BDTFL performs better than JDA on each task,which verifies the discriminative information is vital to the transfer feature learning.
(2) Results on the CMU-PIE dataset (Table 3):On the most tasks,BDTFL performs better than the others.The target aver-age classification accuracy is 67.7%,4.2% more than the best baseline DTSL.On C05→C27 and C29→C05 tasks,our method obtains significant performance improvements of 6.2% and 6.9%compared to the best baseline DTSL.
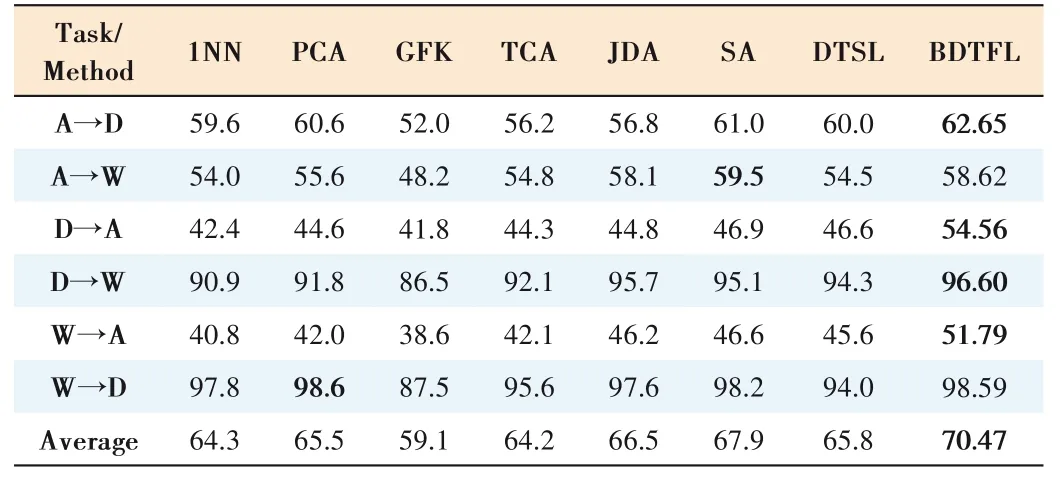
▼Table 2.Accuracy(%)on Office-31(Decaf7)Datasets
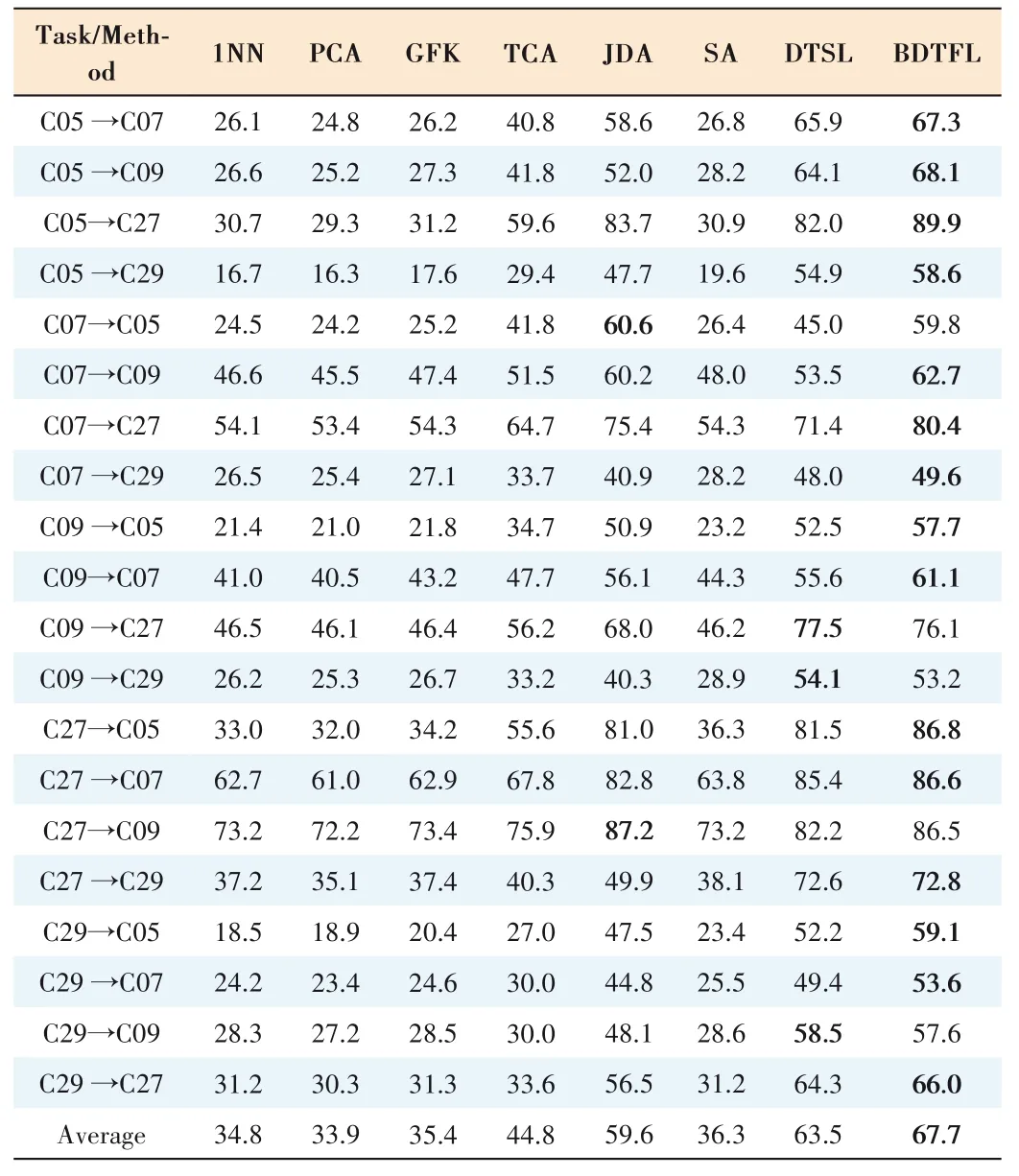
▼Table 3.Accuracy(%)on CMU-PIE Datasets
5 Conclusions
In this paper,we propose a novel method called BDTFL,which adaptively balances the relationship of the marginal distribution matching and the conditional distribution matching and captures the category discriminative information.The adaptive feature matching encourages the overlap between the source domain and target domain to be more accurate.And the category discriminative information can make samples sharing the same label close and clusters with different labels far away from each other,which can further boost the conditional distribution matching across domains.The discriminative information is exploited to alleviate category confusion during the domain-wise alignment.With the assistance of discriminative information,the source classifier can be well transferred to the target domain and boost target classification performance.Our experiments verify the superiority of BDTFL.

- ZTE Communications的其它文章
- Robust Lane Detection and Tracking Based on Machine Vision
- M?IRSA:Multi?Packets Transmitted Irregular Repetition Slotted Aloha
- Feasibility Study of Decision Making for Terminal Switching Time of LEO Satellite Constellation Based on the SGP4 Model
- Advanced Space Laser Communication Technology on CubeSats
- Adaptability Analysis of IP Routing Protocol in Broadband LEO Constellation Systems
- Satellite E2E Network Slicing Based on 5G Technology