
How to Make L2 Easier to Process? The Role of L2 Proficiency andSemantic Category in Translation Priming
2014-09-11 09:57XINWANG
當代外語研究 2014年12期
XIN WANG
University of Oxford, UK
HowtoMakeL2EasiertoProcess?TheRoleofL2ProficiencyandSemanticCategoryinTranslationPriming
XIN WANG
University of Oxford, UK
The current study reports four masked translation priming experiments and demonstrates that L2 proficiency plays a role in translation priming but it is not the only factor determining translation priming patterns. Instead, language dominance might be more accurate in predicting priming patterns. Given the asymmetrical representations of L1 and L2 as described by most bilingual models, the conditions to produce L2-L1 priming not only depends on the task, but also the category size in semantic categorization. Relevant results will be discussed in relation to bilingual models. One implication of the current results is that processing L2 in a specific semantic context can be optimal to L2 lexical access.
L2 proficiency, cross-script translation priming, priming asymmetry, Chinese-English bilinguals, the bilingual lexicon
INTRODUCTION
It is often assumed that lexical information is stored at two different levels, one is the lexical representation level (i.e., phonology or orthography) and the other is the semantic representation level (i.e., word meaning) (see Balota, 1994 for a review). Learning a new L2 (i.e. second language) word involves establishing a new L2 form (phonological and orthographic) in memory and associating the form with appropriate meaning representations. In particular, learning a L2 in a foreign context involves associating a newly learnt word to its translation equivalent in the native language (e.g., Jiang & Forster, 2001; Kroll & Tokowicz, 2005). An early but influential model (i.e., the Revised Hierarchical Model) predicts that the early stage of L2 word learning relies on its L1 translation equivalent via lexical links between L1 and L2, but high L2 proficiency would lead to L2 autonomy without referring to L1 in communication through gradual L2 acquisition (Kroll & Steward, 1994; Krolletal., 2002). This model is challenged by other bilingual models (e.g., the Sense Model) and the relevant empirical evidence with regard to how L2 and L1 are interplayed in processing at different proficiency levels (e.g., Finkbeineretal., 2004). The main problem with the RHM is that the lexical between L1 and L2 fails to accommodate priming data (Wang, 2010). Because more and more evidence has showed that bilinguals were not prevented from accessing L2 meaning at the early stages of learning a language, without going through the L1-L2 lexical association route (e.g., Altarriba & Mathis 1997; Brysbaert & Duyck, 2010; Dimitropoulouetal., 2011a; Leeetal., 1992; Tzelgovetal., 1990). Unlike the RHM, the Sense Model argues for a representational difference between L1 and L2 at the semantic level, L1 having more semantic senses than L2. Here, “sense” is defined as a particular meaning associated with a word. The Sense Model starts with the assumption that most words are polysemous and that the range of senses that a word has differs across languages. Translation equivalents share one sense (typically, the dominant sense), but may differ in the remaining senses. For example, the English wordblackand the Chinese word 黑are translation equivalents, sharing the core sense (COLOR) in common; however, in English black can also be used to refer to a type of humor or a calamitous day on Wall Street, while in Chinese, 黑can refer to those who are evil-minded or something that is secret. Thus, the senses of L1 and L2 words can extend well beyond the shared semantic sense that determines translation equivalence. Since bilinguals are normally more proficient in their L1 than L2, it follows that an L2 speaker would likely know fewer senses of L2 words compared with L1 words. This would result in a representational asymmetry between L1 and L2 at the semantic level. Plausibly, L2 semantic senses develop as L2 proficiency increases. As a result, the RHM predicts high L2 proficiency would lead to direct access to L2 concepts while low proficiency would rely on L1 translation equivalents to access L2 concepts. On the other hand, the Sense Model predicts higher L2 proficiency would lead to richer semantic senses in L2. L2 development can be reflected in the way L2 words are processed and represented in relation to both their L1 translation equivalents and their corresponding conceptual representations.
One way to test the relative difference between L1 and L2 in processing and representation is to adopt the masked priming paradigm in bilingual research (Forster & Davis, 1984). The current study reviews the existing masked translation priming studies and empirically addresses the issue of whether the level of L2 proficiency affects masked translation priming effects and its implications for bilingual models.
MASKED TRANSLATION PRIMING
The masked translation priming paradigm has been adopted in psycholinguistics research to investigate how lexical entries in L1 and L2 are linked in bilinguals (Davisetal., 2003; Dimitropoulouetal., 2011a; Finkbeineretal., 2004; Gollanetal., 1997; Grainger & Frenck-Mestre, 1998; Jiang, 1999; Jiang & Forster, 2001; Pereaetal., 2008; Wang & Forster, 2010; Wang, 2013). In these experiments, a pattern mask was first presented for 500ms (e.g., ####), followed by a pair of prime-target words. The target word (e.g.,HOUSE) in one language was primed by a translation-equivalent word in the other language (e.g., 房子) or preceded by an unrelated word (e.g., 石頭). The prime (e.g., 房子) was very briefly presented (40-60ms) and immediately followed by the target (HOUSE, see Figure 1). Due to the brief presentation of the prime and the pattern mask, participants are usually unaware of the presence of the prime (see Kinoshita & Lupker, 2003 for a review). The benefit of using this paradigm is that it taps into the early automatic processes rather than the conscious strategic processes that the participants could develop after being trained on several trials. For example, a translation relation between 房子-HOUSEcan be detected if 房子s visible and the similar kind of relation will be expected on future trials. However, in a masked priming paradigm, the participant is not aware of the prime 房子 and of course can not strategically process the targetHOUSE. Additionally, subjects would not derive any benefit from a retroactive strategy, in which the relatedness of the target and the prime acts as a cue for the decision. In measurement, response times and error rates on primed target words (e.g., 房子-HOUSE) are compared to unprimed cases (e.g., 石頭〗-HOUSE). A priming effect is observed when the primed target is responded to faster than the unprimed target, and interpreted as indicating that the lexical entries in both languages are linked in some way (either at the lexical level or semantic level or both).

Figure 1 Presentation of a trial in the masked translation priming paradigm
Early work with this technique suggested that translation priming was restricted to cognate terms across alphabetic languages (e.g., de Groot & Nas, 1991; Sanchez-Casasetal., 1992), but subsequent research using languages with different scripts showed that non-cognates also produced strong translation priming (e.g., Finkbeineretal., 2004; Forster & Jiang, 2001; Gollanetal., 1997; Grainger & Frenck-Mestre, 1998; Jiang, 1999). In particular, Forster and Jiang (2001) reasoned that cross-script translation priming had to occur at the conceptual level because priming could not occur at the form level. That is, for a Chinese-English bilingual, if 房子 produces a faster response toHOUSE, 房子 andHOUSEare integrated at the semantic level in the bilingual mental lexicon, rather than lexical level (orthography or phonology). Therefore, this translation priming effect is considered resulting from the automatic activation of the common conceptual node between the prime and target, as some language pairs simply do not overlap at the lexical levels, such as the case with Chinese-English bilinguals.
A well-established finding associated with translation priming isprimingasymmetry. In different bilingual populations, it has been found that priming is only obtained from L1 to L2, but not for the reverse direction, in lexical decision tasks (e.g., Dimitropoulouetal., 2011b; Gollanetal., 1997; Jiang, 1999). In lexical decision, participants are asked to judge whether the target word is a word or nonword in the target language. Researchers have tried to create optimal conditions to obtain L2-L1 priming, but often failed (e.g., Jiang, 1999; Wang & Forster, in press). Yet, a variant of priming asymmetry is to demonstrate a smaller magnitude of L2-L1 priming effects compared to L1-L2 priming, as reported by a few studies that did observe L2-L1 priming (e.g., Schoonbaertetal., 2009). These results suggest that L1 primes are more effective than L2 primes in lexical decision and imply that lexical representation of L1 automatically activates its translation equivalent and hence facilitates recognition of the target L2 (Neely, 1991). The issues remain why L2-L1 priming was absent and language directions would affect the priming pattern.
Most researchers attribute the failure to obtain L2-L1 priming to low L2 proficiency levels (e.g., Basnight-Brown & Altarriba, 2007). The proficiency account is reasonable but also inadequate for two reasons. First, the measurement of proficiency is hard to standardize and it varies across studies. In fact, Xia and Andrews (2014) state that proficiency does not appear to play a systematic role in determining the priming pattern, based on published translation priming work. Second, proficiency fails to explain two sets of masked priming results: within-L2 repetition priming (i.e. L2housecan primehouse) and cross-language cognate effects (Wang, 2013). In order to find out whether L2 primes were not as effective as L1 primes as the source of the absence of L1-L2 priming, Jiang (1999) conducted a series of experiments and consistently obtained within-L2 repetition priming. Similar results were also obtained by Gollanetal. (1997) as well. Lack of L2 proficiency would predict ineffective L2 processing and thus no within-L2 repetition priming, which was not the case in the abovementioned experiments. Additionally, other studies have found strong priming effects on cognate translations (words with similar phonology and orthography, e.g., rico-RICH as a Spanish-English pair) in both directions (L1-L2 and L2-L1), but not on non-cognate translations (e.g., Sanchez-Casasetal., 1992). In particular, two studies systematically investigated the role of proficiency in modulating priming patterns but still found null effect from L2 to L1. Davisetal. (2010) tested three groups of bilinguals of different proficiency levels: English-dominant, Spanish-dominant and balanced Spanish-English bilinguals. Priming was observed in both directions with all three groups for cognates, but not for non-cognates. This contrast suggests that cross-language priming occurs at the level of form rather than meaning, regardless of the proficiency level. Dimitropoulouetal. (2011b) tested three groups of Greek-English bilinguals of different proficiency levels and found the same priming pattern across all groups: larger priming effect from L1-L2 than L2-L1. Therefore, these recent results pose challenges to the proficiency account as an explanation of the masked translation priming patterns.
TASK-DEPENDENTEFFECTSINTRANSLATIONPRIMING
The most puzzling aspect of this asymmetry is its dependence on task. When the task is switched to semantic categorization (e.g., is it an animal?), the asymmetry disappears and translation priming is restored in the L2-L1 direction (Finkbeineretal., 2004; Grainger & Frenck-Mestre, 1998; Wang & Forster, 2010; Xia & Andrews, 2014). In semantic categorization, participants were given a category (e.g.,animal) and asked to judge whether the given target word belonged to that category or not. For example, Grainger & Frenck-Mestre (1998) tested highly skilled English-French bilinguals in both lexical decision and semantic categorization using the masked priming paradigm. Non-cognate translation equivalents of English and French were selected to serve as primes and targets. Prime words were always presented in French (L2) and target words always in English (L1). The results showed that reaction times in semantic categorization and lexical decision tasks were similar. However, there was a robust translation priming effect in the semantic categorization task, but not in the lexical decision task. Grainger and Frenck-Mestre (1998) proposed that this task effect followed logically from the fact that semantic categorization requires access to semantic information whereas lexical decision does not. They argued that the translation priming effects observed with the highly proficient bilinguals were mediated by semantic representations shared by translation equivalents and not by excitatory connections between distinct form representations. However, this explanation of the task effect does not account for the existence of L1-L2 priming in lexical decision. If lexical decision does not require access to semantic information, then why has L1-L2 translation priming been consistently observed in this task in several earlier studies, in particular, with cross-script bilinguals?
Both Finkbeineretal. (2004) and Wang and Forster (2010) reported L2-L1 priming in semantic categorization while absent in lexical decision with cross-script bilinguals. The results suggest that bilinguals were able to activate the semantic representations of L2 primes in a suitable task. Similarly, L2 primes were as effective as L1 primes in an episodic recognition task, but not in lexical decision (Jiang & Forster, 2001; Witzel & Forster, 2012). Why does L2-L1 priming occur in a semantic categorization task? According to the Sense Model, the category information restricts the sense activation of the targets. That is, only category-relevant senses associated with the target are critical to performing the task (e.g., an animal or not?) and prime activation of category-relevant senses is proportionally sufficient in both directions to produce priming. In other words, L2-L1 priming is a result of restricted semantic activation by the category information. Thus, the Sense Model is successful in explaining the translation priming patterns, namely the priming asymmetry and task-dependent effect observed with various bilingual groups (Finkbeineretal., 2004; Gollanetal., 1997; Jiang, 1999; Wang & Forster, 2010); while other models would encounter difficulties to account for the task-dependent effects.
MASKEDTRANSLATIONPRIMINGANDL2PROFICIENCY
As discussed above, the proficiency account itself is not adequate to explain priming asymmetry. However, recent findings have reported symmetric priming with highly proficient balanced bilinguals (e.g., Dunabeitiaetal., 2010a; Pereaetal., 2008; Wang, 2013). Wang (2013) compared two groups of highly proficient Chinese-English bilinguals, one being balanced and the other English-dominant. The results showed robust translation priming of similar magnitude in both directions with the balanced Chinese-English bilinguals, but only L1-L2 priming with the English-dominant bilinguals. This contrast indicates language dominance modulated the priming pattern and suggests that translation priming is a result of the amount of reading experience with the prime language. Language proficiency and language dominance are closely related (see a discussion in Wang, 2013), but are indeed different measures of a bilingual’s linguistic profile.
Nevertheless, in line with all the available masked translation priming evidence, a bilingual’s L2 proficiency would be expected to play a role in predicting translation priming effects as well as theoretical models. In fact, a quick survey of published work showed that most studies have opted for testing relatively high proficient unbalanced bilinguals with college-level knowledge of their L2 for practical reasons (Dimitropoulouetal., 2011a). In addition, L2 proficiency measures of different populations in different studies can vary much, which makes comparisons difficult. To further understand the role of L2 proficiency in translation priming, it is necessary to control the variable of proficiency. It hasn’t been reported in the literature whether priming effects differ by L2 proficiency with the same set of stimuli, with cross-script bilinguals, such as Chinese-English ones. Therefore, the current study will focus on unbalanced bilingualism because the available evidence demonstrating symmetric priming effects appears to occur in balanced bilinguals whose two languages are somewhat equally developed (Dunabeitiaetal., 2010a, b; Wang, 2013).
The majority of translation priming studies is based on alphabetical languages, namely, bilinguals’ two languages involve the same writing systems. Only a handful of studies have reported translation priming with cross-script bilinguals, esp. those whose two languages involve different writing systems (logographic and alphabetic) (e.g., Finkbeineretal., 2004; Jiang, 1999; Wang, 2013). Critically, all the cross-script studies reported L1-L2 priming only, except for a balanced group in Wang (2013). That is, with cross-script bilinguals, priming asymmetry seems to be consistent across studies in lexical decision even with highly proficient bilinguals. This poses a challenge if proficiency needs to be systematically manipulated to understand its relation to priming patterns, as low proficiency bilinguals are unlikely to produce L2-L1 priming in lexical decision if it was even difficult to observe L2-L1 priming in high proficiency bilinguals. Thus the lexical decision task would not allow us to find the interested effect. An alternative solution to this problem is to use the semantic categorization task, which has been shown to restore L2-L1 priming in various studies with highly proficient bilinguals (Finkbeineretal., 2004; Wang & Forster, 2010; Xia & Andrews, 2014). One way to understand the role of proficiency in L2-L1 priming is to see whether a similar effect would emerge in both low and high proficiency groups in the same study. If L2 proficiency plays a role in translation priming, as most models assume, we would expect to observe a weak or null effect from L2 to L1 in low proficiency bilinguals in the semantic categorization task, as compared to a robust L2-L1 effect in high proficiency bilinguals. Experiment 1 and 2 serve to test this hypothesis.
PROFICIENCYEFFECTSINSEMANTIC
CATEGORIZATION
Experiment1
The purpose of this experiment is to investigate whether bilinguals of different proficiency levels in L2 would show a similar or different L2-L1 priming effect in semantic categorization. Two groups of Chinese-English bilinguals were selected based on their length of immersion in an English-speaking country and their self-reported ratings of English skills (see Table 1). All of them were native speakers of Chinese and studied English as a foreign/second language. The high proficiency group was recruited at the University of Arizona, USA, and had lived in the USA for at least one year and a half by the time of testing. They all received a minimum of 8 years of English instruction in China before they came to USA for undergraduate or graduate degrees. The low proficiency group was recruited in China and had received a minimum of 8 years of formal English instruction in China before they were enrolled as undergraduates at Shen Zhen University. However, unlike the bilingual participants recruited in the USA, they did not have any language immersion experiences in an English-speaking country. This might indicate that they had much fewer experiences with L2, and consequently, their L2 proficiency was lower than that of those immersed in USA.
Method
Participants: Thirty-six Chinese-English bilinguals were recruited as low proficiency participants in China. Twenty-four Chinese-English bilinguals were recruited as high proficiency participants in the USA. They all voluntarily participated in the study and were not paid.
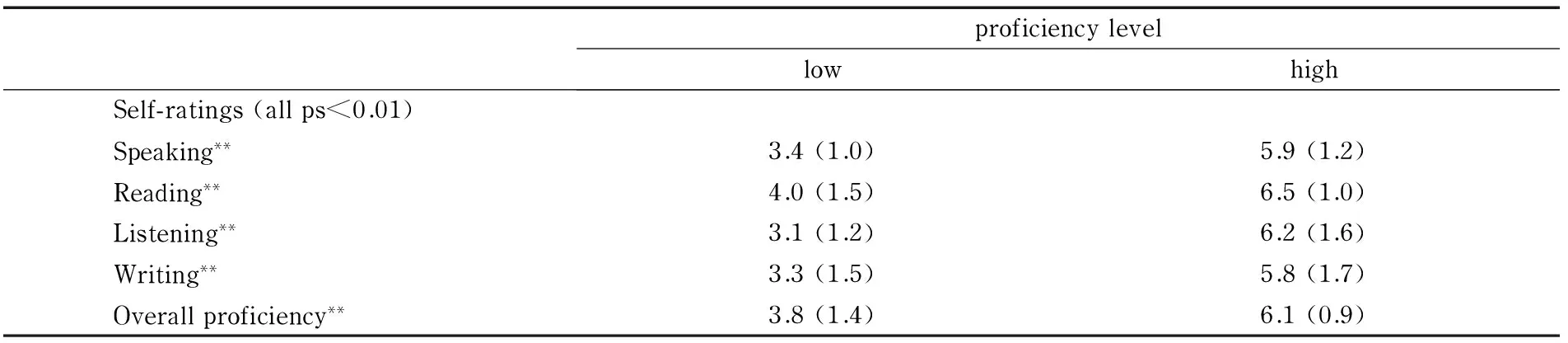
Table 1 Mean scores (SD) of self-rated L2 proficiency by the low and high proficiency group (1 being the least proficient; 7 being the most proficient)
Materials and Design: The items and design were adopted from Wang and Forster (2010). The independent variables were Prime Type (translation vs. congruence vs. unrelated) and Membership Type (exemplar vs. non-exemplar). The dependent variables were reaction times and accuracy. In total, there were 10 categories, each with 9 exemplars and 9 non-exemplars. In addition, 10 practice items were also selected. Three conditions were created in each category for both exemplars and non-exemplars: L1 Chinese target words were preceded by (1) English translation primes (i.e. translation condition: e.g.,room-房間), (2) English exemplar primes (i.e., congruent condition: e.g.,office-房間) or (3) English unrelated primes (i.e., unrelated condition: e.g.,good-房間). Three counterbalanced lists were constructed so that the target preceded by its translation prime on List A was preceded by an exemplar prime on List B and an unrelated prime on List C.
Items were blocked and randomly presented within each category. Following the practice category, the order of presentation of the other categories was randomized.
Procedure: Each trial consisted of the following sequence, as in the standard three-field masked priming paradigm: the trial started with a 500ms forward mask (########), followed by an English prime (translation or control) in lowercase letters for 50ms, and then the Chinese target word for 500ms. No participant reported seeing the English words preceding the Chinese targets, and all were surprised during the debriefing to learn that any English word had been presented.
Participants were asked to read written instructions in Chinese before they performed the task. No mention was made of the possible existence of the primes, nor the fact that their knowledge of English might be involved in the experiment. Prior to the presentation of targets within each category, they were given the category information on the computer screen and asked to decide whether the following presented targets belonged to the indicated category or not by pressing either a YES button or a NO button as quickly as possible. This stimulus presentation and timing of responses was controlled by the DMDX package developed at the University of Arizona by J.C. Forster (Forster & Forster, 2003).
ResultsandDiscussion
In analyzing the results of this experiment and all subsequent experiments, data from trials on which an error occurred were discarded and outliers were treated by setting them equal to cutoffs established at two standard deviations above or below the mean for each participant. Participants who made errors on more than 25% of the trials would have been excluded from the analysis, but none made more than 25% errors. The results from the low proficiency group were shown in Table 2 and from the high proficiency group in Table 3, respectively.

Table 2 Mean Semantic Categorization Times (RT in milliseconds) and Error Rates (ER in percentages) for both exemplars and non-exemplars from L2 to L1 in the low proficiency group

Table 3 Mean Semantic Categorization Times (RT in milliseconds) and Error Rates (ER in percentages) for both exemplars and non-exemplars from L2 to L1 in the high proficiency group
Low proficiency group: Two-way ANOVAs showed that neither a translation effect nor a congruence effect was significant for either exemplars or non-exemplars. In addition, the mean error rates (6.9%) did not differ significantly between conditions for both exemplars and non-exemplars.
High proficiency group: As shown in Table 3, mean response times were 513ms in the translation prime condition, which was significantly faster than the unrelated condition (525 ms) by both subject and item analyses:F1(1, 21)=17.27,p<0.01;F2(1, 87)=6.25,p=0.01. When compared to the congruent condition (518ms), the translation effect was significant in the subject analysis, but not in the item analysis:F1(1, 21)=4.47,p=0.047;F2(1, 87)=1.01,p=0.317. A separate analysis of the congruent and unrelated conditions showed no congruence effect from L2 to L1:F1(1, 21)=2.85,p=0.11;F2(1, 87)=1.39,p=0.24. In addition, the mean error rate was 3.3% and did not differ significantly between conditions for exemplars. The non-exemplars did not show any advantage for translation primes (562 ms) compared with the exemplar controls (564ms), nor unrelated primes (561ms):F1(2, 42)=0.21,p=0.81,F2(2,174)=0.46,p=0.63. The mean error rate was 4.2% and did not differ significantly between conditions for non-exemplars. These results demonstrate the contrast between the low proficiency group and high proficiency group: robust L2-L1 priming was observed in the high L2 proficiency group, but not in the low L2 proficiency group in the semantic categorization task. In addition, these results indicate that L2 proficiency plays a role in translation priming. One might argue that the low proficiency group needed more time to effectively process L2 primes, in order to produce priming effects (Schoonbaertetal., 2009). Experiment 2 serves to test this possibility by inserting a backward mask (150ms) to see whether L2-L1 priming could be observed with the low proficiency group.
Experiment2
The purpose of Experiment 2 was to ensure enough time for the participants to process the L2 primes by including a backward mask (cf. Jiang, 1999).
Method
Participants: Same as the low proficiency group in Experiment 1, but recruited on a separate day to test the same materials.
Materials and Design: Same as Experiment 1.
Procedure: Same as Experiment 1, except that an 150ms backward mask (&&&&) was inserted between the prime and target. It is important to note that the backward mask (&&&&) differed from the forward mask (####) so as to limit the visibility of the prime. This presentation sequence prevented the participants from being aware of the existence of the prime.
ResultsandDiscussion
The data trimming procedure was the same as in Experiment 1 and none of the participants were excluded from data analysis. Table 4 presents the results from the same group of low proficient bilinguals when given a longer time to process L2 primes.

Table 4 (with backward masks) Mean Semantic Categorization Times (in milliseconds) and Error Rates (in percentages) for both exemplars and non-exemplars from L2 to L1 in the low proficiency group
Again, two-way ANOVAs showed that neither a translation effect nor a congruence effect was significant for either exemplars or non-exemplars. This pattern was consistent with Experiment 1, no L2-L1 priming was observed. In addition, the mean error rates did not differ significantly between conditions for exemplars (5.7%) and non-exemplars (9.5%). However, there was an effect of Membership Type in error rates, but not reaction times. That is, participants seemed to make more errors in responding to non-exemplars than exemplars. This result was different from Experiment 1. Overall, these results indicate that the backward mask did not make a difference in producing L2-L1 priming.
One might question whether these less proficient bilinguals actually knew the meanings of the experimental items in English. To ensure that the low proficiency group could effectively process the English items both online and offline, Experiment 3 serves to test whether a L1-L2 priming effect could be replicated in this group, followed by a vocabulary test to estimate the participants’ L2 vocabulary.
Experiment3
The purpose of Experiment 3 is to establish the priming asymmetry in the low proficiency group in the semantic categorization task. Therefore, the same low proficiency participants were tested in the reversal language direction. The prediction is that bilingual participants should produce L1-L2 priming in semantic categorization, as consistently demonstrated in lexical decision in the literature, if they could recognize the given L2 words.
In addition, it is important to note the priming pattern across exemplars and non-exemplars. In Experiment 1 with high proficiency group, translation priming was only observed on exemplars. This fits with the prediction of the Sense Model: category information should not restrict the semantic processing of non-exemplars. However, L1-L2 translation priming should be observed for both exemplars and non-exemplars because L1 always has richer semantic representations than L2. According to the Category Restriction Hypothesis (see Wang & Forster, 2010), we should expect stronger priming for exemplars than non-exemplars because processing exemplars focuses on the category-relevant senses.
Method
Participants: Same as the low proficiency group in Experiment 1 and 2, but recruited on a separate day to test the same materials.
Materials and Design: Same as Experiment 1, except that all the targets were the English translations of the Chinese words given in Experiment 1 and 2. Subsequently, all the primes were switched to L1 Chinese. For both the translation and congruent conditions, the items were kept consistent with those in Experiment 1 and 2, except that the presentation sequence of each trial is changed to the Chinese prime preceding its corresponding English target. For the unrelated condition, a total of 60 different Chinese two-character words were selected so that they were unrelated either to the category information or translation items. These Chinese words were matched in frequency and number of stroke.
Procedure: Same as Experiment 1. Ten practice items were presented prior to the experimental trials. None of the participants reported aware of the existence of the Chinese primes.
ResultsandDiscussion
Data trimming followed the same procedure in Experiment 1 and none of the participants made errors more than 25%. Table 5 presents the results from the same group of low proficient bilinguals when tested in the L1-L2 direction.

Table 5 Mean Semantic Categorization Times (in milliseconds) and Error Rates (in percentages) for exemplars and non-exemplars from L1 to L2 in the low proficiency group
The mean response times were 666ms in the translation condition for exemplars; significantly faster than 702ms in the congruent condition and 715ms in the unrelated condition for exemplars in both participant and item analyses,F1(2, 42)=13.34,p<0.05;F2(2, 174)=16.08,p<0.05. As expected, there was a strong translation priming effect (49ms) from L1 to L2. Like Experiment 1, a weak congruence effect (13ms) was observed, but it was not significant. The mean error rates for the translation and congruence conditions differed significantly from the unrelated condition for exemplars in both subject and item analyses:F1(2, 42)=9.54,p<0.001;F2(2, 174)=15.72,p<0.001. This shows that participants made significantly less errors when L1 primes were category-related (i.e., translations or category exemplars), which suggests that they might be trying to categorize both primes and targets.
In the analysis of non-exemplars, significant translation priming of 30ms was observed:F1(1, 21)=10.00,p=0.004;F2(1, 87)=5.70,p<0.05, as well as a congruence effect (inhibitory effect) of 26ms:F1(1, 21)=9.15,p=0.006<0.05;F2(1, 87)=4.68,p=0.03<0.05. Planned comparisons showed that the mean error rates between the translation and unrelated conditions differed from each other significantly in participant analysis but not in item analysis:F1(1, 21)=8.92,p=0.007<0.05;F2(1, 87)=1.85,p=0.178. However, there was a significant difference in error rates between the unrelated and incongruent conditions in both participant and item analyses:F1(1, 21)=6.73,p=0.027;F2(1, 87)=5.28,p=0.024. The translation effect shows that participants’ L1 facilitated the recognition of its translations, similar to the translation effect observed in exemplars. The ‘congruence effect’ suggests that participants might have categorized the primes, otherwise, why is the response to 大門 (gate)-rainmuch slower than that to 回應(yīng) (answer)-rainin the category ofPartoftheBuilding? In the case of non-exemplars, categorization carried out on the exemplar primes (i.e. yes response) was incongruent with the categorization on the targets (no response), compared to the translation and unrelated conditions where both prime and target would generate the same no responses. Thus the incongruence in the exemplar prime condition produced an inhibitory effect that supports the idea that categorization was also carried out on the primes. The error patterns across conditions for non-exemplars were consistent with those for exemplars, further suggesting participants may categorize the primes and benefit from those word pairs that were congruent in response.
Four lexical items were randomly selected from the ten categories used in the task. Two of them were presented in English and the other two in Chinese in the pencil and paper test. After the experiments, all the participants were asked to translate the English items into their Chinese equivalents and the Chinese ones into their English equivalents. In total, they were tested with 20 English items and 20 Chinese items. The results showed that the average error rate for the Chinese-English translation was 21.5% and for the English-Chinese translation was 24.5%. Evidently, the lack of L2 vocabulary is not the explanation of the absence of the translation priming. It is their low proficiency level in L2 that caused a much weaker and less effective semantic activation, so that the priming effect disappeared in Experiment 1.
In summary, both translation and congruence effects were observed from L1 to L2 in the low proficiency group in semantic categorization. First, the data showed that the low proficiency group was capable to recognize the given L2 items, but they obviously made much more errors (mean error rate of 16.2%) than recognizing L1 items (Exp. 1) (mean error rate of 6.9%). This same pattern is also observed in their reaction times: the mean of 569ms in L1 recognition vs. 753ms in recognizing L2 translations. Second, the current results confirm the priming asymmetry with the low proficiency group: robust L1-L2 priming, but not vice versa. Third, as expected, these results demonstrate strong L1-L2 priming effects for both exemplars and non-exemplars, which is different from the L2-L1 priming effects as reported in the literature. In particular, the exemplars showed a stronger priming effect (49ms) than the non-exemplars (30ms), which suggests that a category focusing effect produced more priming for exemplars. Therefore these results are in line with the Category Restriction Hypothesis, assumed by the Sense Model.
According to the Category Restriction Hypothesis, the category-irrelevant senses are restricted in activation. However, it is unknown why the category can be effective in producing L2-L1 priming yet an explicit semantic task (e.g., is it bigger than a brick?) failed to do so (see a detailed discussion in Wang & Forster, 2010). So far, Experiments 1-3 have demonstrated priming asymmetry in semantic categorization and established the role of proficiency in translation priming. If the category itself (e.g., is it an animal or not?) is the most critical factor in L2-L1 priming, it is important to understand whether category size could affect priming patterns, as category size turns out to be relevant in the monolingual literature (Forster, 2004, 2006). For example, Forster (2006) found that the neighborhood (N) interference effect was significant for nonword targets that were neighbors of exemplars when the category wasanimal(small category) but absent when the category wasphysicalobject(large category). That is, it took subjects longer to rejectturpleas a nonword exemplar than cishop in theanimalcategory. This indicates that the neighbor ofturple, which isturtle(exemplar of ananimalcategory), was activated to cause interference. Why doesn’t the neighbor ofcishop, which isbishop(non-exemplar), produce the same effect? It could be due to the fact that the non-exemplar distractor,cishop, has a non-exemplar neighbor,bishop①. But this effect was not observed in thephysicalobjectcategory. Additional evidence shows that there is an ambiguity disadvantage observed when a large category (living thing) is used, but not when a small category (animal) is used (Hinoetal., 2002; Forster, 2006). That is, it takes longer to decide that an ambiguous word such asbankis not a living thing, and this indicates that both meanings are activated to be tested for compatibility with the category. However, once the category becomes smaller, such as animal, this ambiguity effect disappears (Pexmanetal., 2004).
We can think of lexical decision as a task where participants made decisions based on two big categories (word vs. nonword), while semantic categorization restricted participants’ decision-making processes to small categories. If a categorize size effect was found in translation priming, we could learn more about the task-dependent effect in translation priming and relevant models (e.g., the Links Model, Forster & Hector, 2002). Experiment 4 serves to test whether category size could affect L2-L1 priming effects.
Experiment4 (CategorySizeEffects)
Method
Participants: The same Chinese-English bilinguals in the high proficiency group in Experiment 1 were recruited for this experiment.
Materials and Design: The Chinese-English word pairs were selected by the same procedure used in Experiment 1 as in Wang and Forster (2010). Two Chinese-English bilinguals were asked to provide translation equivalents from English to Chinese; another two did the reverse direction. The ones that matched in two directions were used as test items.
Two large categories were adopted:livingthingvs.non-livingthingandman-madevs.non-man-made. In order to compare the priming pattern of both directions (L1-L2 and L2-L1), thelivingthingcategory was designed to test the L1-L2 direction while the L2-L1 direction was tested in theman-madecategory. Forty-eight Chinese-English word pairs were selected for both categories, including twenty-four exemplars and the same number of non-exemplars. In theman-madecategory, the items were presented as English targets preceded by masked Chinese primes; while the Chinese targets were preceded by masked English primes in thelivingthingcategory. Both categories included three conditions: translation primes, exemplar primes, and unrelated primes. The exemplar primes were the category members but not the targets’ translation equivalents, in order to avoid a congruence effect as discussed in Wang and Forster (2010). To counterbalance the materials, an additional 48 English words were selected as exemplar primes and another 48 as unrelated primes for theman-madecategory. These English words were matched in frequency and length in CELEX (Baayenetal., 1995). Similarly, 48 Chinese words were selected as exemplar primes and another 48 as unrelated primes for thelivingthingcategory. All the Chinese items in the two categories were two character words and were matched in frequency.
Three counterbalanced lists were generated so that each word (either in L1 or L2) was observed in the three conditions. The exemplar and control primes were always different words but matched with their compared translation primes in length and frequency.
Each list was presented as two blocks of an equal number of items. One block of Chinese targets (L2-L1) was followed by the other block of English ones (L1-L2). The items in both categories were randomly presented. Preceding each block, there were 10 practice trials so that the subjects not only were familiar of the presentation but also of the language to respond to.
Procedure: The method of presentation was exactly the same as in Experiment 1 and 3 in both L1-L2 and L2-L1 directions.
Participants read instructions in Chinese before the experiment and were aware that both languages would be tested. They were randomly assigned to each of the three lists. They were asked to respond “YES” to a category member and “NO” to those that were not category members. None of them reported seeing the primes after the testing.
ResultsandDiscussion
Following the same data trimming procedure, two of the participants were excluded in analysis as they made more than 25% errors. The mean classification times and error rates in both priming directions are shown in Table 6 for exemplars and Table 7 for non-exemplars.

Table 6 Mean Semantic Categorization Times (in milliseconds) and Error Rates(in percentages) for exemplars in L1-L2 and L2-L1 directions (Experiment 4)

Table 7 Mean Semantic Categorization Times (in milliseconds) and Error Rates(in percentages) for non-exemplars in L1-L2 and L2-L1 directions (Experiment 4)
The L1-L2 translation priming was significant for both exemplars and non-exemplars in both participant and item analyses by two-way ANOVA [exemplars:F1(2, 66)=4.17,p=0.02;F2(2, 42)=3.99,p=0.03. non-exemplars:F1(2, 60)=4.78,p=0.02; F2(2, 42)=6.33,p=0.004]. There was a 39ms translation effect on exemplars and a 42ms effect on non-exemplars. The mean error rate was 18.6% for exemplars and 7.3% for non-exemplars and did not differ significantly between conditions. Furthermore, planned comparisons showed that translation priming was significant to both congruent conditions and unrelated conditions. However, there was no congruence effect. Unlike Experiment 1, where L2-L1 priming was observed for the high proficiency group, Experiment 4 failed to observe any L2-L1 priming effect when the category was large. This shows that L2-L1 priming could only be observed when the category was small. However, the category size was irrelevant to L1-L2 priming, which is reasonable because L1-L2 priming was consistently obtained in lexical decision. These results suggest that category size is critical in translation priming.
GENERAL DISCUSSION
To summarize the current results: Experiment 1 and 2 demonstrated that the less proficient bilingual group failed to produce L2-L1 priming in semantic categorization, regardless of with or without a backward mask. This priming pattern was different from the high proficiency bilingual group who demonstrated L2-L1 priming in semantic categorization, which is consistent with what was reported in the literature. To establish the priming asymmetry for the low proficiency bilingual group, Experiment 3 demonstrated robust translation priming effects from L1 to L2 in semantic categorization, as well as a marginal congruence effect from L1 to L2. These results suggest that L2-L1 priming observed in the current and previous studies can be associated with L2 proficiency level. To further understand the L2-L1 priming mechanism, Experiment 4 continued to examine whether category size is a factor modulating priming patterns. The results showed that L2-L1 priming disappeared with bigger categories. The contrast between Experiment 1 and 4 in the high proficiency group suggests that category size can be associated with L2-L1 priming effects.
These results reveal two key findings: First, L2 proficiency plays a role in translation priming but is not the only explanation for priming asymmetry observed in the high proficiency bilingual group; Second, only small categories can restore L2-L1 priming in semantic categorization with the high proficiency bilingual group, which means that L2-L1 priming occurs under rather restrictive conditions that are optimal for L2 primes to be effective.
L2ProficiencyEffects
The asymmetry revealed in semantic categorization for the low proficiency group suggests that priming depends on the proficiency level of L2. A low proficiency in L2 can result in null priming not only in lexical decision, but also in semantic categorization. How do the current results fit with other translation priming studies? In a few reports on translation priming with semantic categorization (e.g., Finkbeineretal., 2004; Wang & Forster, 2010; Xia & Andrews, 2014), consistently, robust L2-L1 priming was observed with exemplars, but not with non-exemplars. In addition, most previous priming studies showed null effects from L2 to L1 in lexical decision with cross-script bilinguals (e.g., Gollanetal., 1997; Jiang, 1999), except for the highly proficient balanced Chinese-English bilinguals demonstrated in Wang (2013). Here, the current results demonstrated a contrast between the high proficiency and low proficiency group in L2-L1 translation priming with exemplars in semantic categorization. Taken together, a conclusion can be drawn is that L2 proficiency should reach certain level in order for L2 primes to be effective in semantic categorization and that L2-L1 priming can only be observed with highly proficient balanced bilinguals in lexical decision. In a recent measure, Wang and Forster (in press) demonstrated different degrees of semantic awareness of primes in L1 and L2 at various prime durations and suggested that the mechanism of translation priming is more like automatic spreading activation (Neely, 1977; Posner & Snyder, 1975): the prime activation alters the status of the lexical representation of its counterpart in the other language as the target, so that it is recognized faster. This is an automatic process based on the visual input: a more automatic processing from form to semantics in L1 can facilitate the recognition in L2, but a less automatic processing in L2 would fail to facilitate the recognition of L1; thus producing no priming in the L2-L1 direction. This automaticity depends on readers’ proficiency in the language, rather than the prime duration. Thus, we should assume a prerequisite for L2-L1 priming, which is, L2 automaticity should be good enough to facilitate L1 target recognition.
Nevertheless, L2 proficiency is not the only explanation for priming asymmetry observed in lexical decision. For instance, priming asymmetry persists with unbalanced bilinguals of different levels of L2 proficiency in a recent study (Dimitropoulouetal., 2011b). In other words, L2 proficiency does not determine priming patterns by itself. What might determine the priming pattern then? In fact, an overview of the translation priming literature suggests that there is an effect of language dominance with respect to the pattern of early and automatic cross-language effects. It appears that priming asymmetry is usually observed with unbalanced bilinguals whose native language is more dominant than L2 while symmetric priming starts to emerge with balanced bilinguals (e.g., Dunabeitiaetal., 2010a; Pereaetal., 2008; Schoonbaertetal., 2009; Wang, 2013). In particular, with cross-script bilinguals, Wang (2013) demonstrated that unbalanced proficient bilinguals persisted priming asymmetry while balanced bilinguals produced symmetric priming. This evidence suggests thatLanguageDominanceis a more accurate predictor of priming patterns thanLanguageProficiency. Proficiency is an index of general abilities across language processing domains (e.g., Stefani, 1994), particularly, skills in speaking, listening, reading and writing. Language Dominance is a global measure of relative frequency of use and proficiency in each language (Dunn & Fox Tree, 2009). A balanced bilingual, the outcome of the regular usage of both languages, must be proficient in both languages. An L2-proficient bilingual can be functional in L2 in various measures, but still dominant in L1. Taken together, it is safe to conclude that L2 proficiency plays a role in translation priming, esp. for L2 primes to be effective but that priming patterns depend on a more holistic measure of bilinguals’ profiles: language dominance.
CategorySizeEffects
Along with previous results (Finkbeineretal., 2004; Wang & Forster, 2010), it can be concluded that L2-L1 priming not only depends on the task, but also the category size. It seems that the small category functions as a “focusing” device to boost the activation of L2 semantic senses. Why does the “focusing” effect only apply to small categories? The Sense Model implies that a small category is more capable of suppressing the L1 category-irrelevant senses so that the increased proportion of primed L2 senses triggers priming, compared to a big category, like in the lexical decision task, which can be viewed as involving a large category, i.e., word. In this regard, the category size effect is similar to the task effect, caused by the difference in the restriction of L1 sense activation, depending on the category information.
What is the mechanism involved in semantic categorization with a small category that suppresses the L1 category-irrelevant senses? A useful theoretical framework is Forster and Hector’s (2002) Links Model. This model assumes the existence of a header for each lexical entry that specifies the various semantic fields that this word is associated with. To quote an example from Forster (2006), the header forbridgewould contain a link to a broad semantic field that includes buildings, highways, tunnels, etc. It would also contain a link to another field that includes games, hobbies, and other recreational activities. Within the search model of lexical access, this semantic index is assumed to be available at the initial stage of processing when an orthographic comparison is made between the input and the lexical entry. The search process would operate over the close matches, namely those lexical items sharing orthographic overlap with the input; but the verification process, which checks whether the candidate entry matches the input, operates independently of the search and takes the links into account. If the task is to detect category-relevant semantic features, the verification process will check whether a candidate entry has the link to that semantic field. If not, the verification skips to the next candidate on the list. This model implies that the verification process only operates on the candidates with a category-relevant link, given that the experimental category corresponds to an existing semantic field②. Forster (2006) proposed that semantic fields are based on lexical co-occurrence data, i.e. the extent to which two words tend to occur in similar contexts. The co-occurrence index for two words is determined by comparing the distributional profiles of the words, where a profile consists of a vector specifying how often the word occurs in the same context as each other word in the language over a large corpus. As an example, the wordssofaandcouchhave very similar profiles, meaning that the contexts in whichsofaoccurs tend to be the same as the contexts in which couch occurs. Words that have high co-occurrence indices will tend to form semantic clusters. However, it is argued that exemplars of a large category (e.g.,livingthingorphysicalobject), unlike the exemplars of a small category (animal), would have such low co-occurrence indices (on average) that no semantic field would be formed, and hence the lexical entries for exemplars would not contain a link to such a field. Thus, the header on the lexical entry forostrichwould contain a link to an animal field, but not to a field containing living things. This would indicate that the verification process has to rely on the activation of the semantic representation of the lexical entry in order to decide whether a word might or might not belong to the category oflivingthing.
It can be argued that links are involved in sense selection in semantic processing. A word with multiple meanings would have multiple entries, each with its own link. The entry that shares a link with a word or words in the prior context (or which has a high co-occurrence index with such a word) would automatically be selected. The prior context in a semantic categorization task is the category itself. Sense selection for both L2 prime and L1 target will be controlled by the context, which will have a focusing effect. It can be assumed that exemplars share a link in a semantic category and because these links are based on co-occurrence data, they only exist for small categories. If this argument holds, we can expect an automatic sense selection process for exemplars through the links. This link enables the effectiveness of L2 primes and gives rise to priming. However, broad categories will not lead to the formation of links if co-occurrence is involved. Thus, L2-L1 priming will not be obtained in a big category.
BilingualModels
The current results demonstrated effects of proficiency and category size in translation priming in semantic categorization. How do these results fit with current bilingual models? The RHM predicts low L2 proficiency would lead to failure of accessing L2 concepts and could possibly produce L2-L1 priming through L2-L1 lexical links. This is not the case with current results, as L2-L1 priming was absent in semantic categorization with the low proficiency group. One of the assumptions with the Sense Model is that L2 has direct access to meanings from L2 forms. If this was the case, we would expect L2-L1 priming in semantic categorization. Therefore, certain L2 proficiency level is the prerequisite for the Sense Model to work. In addition, other models (e.g. the RHM) would have difficulty explaining the category size effect. The Sense Model would attribute the category size effect to the category focusing mechanism that restrict the activation of L1 senses so as to produce L2-L1 priming. This priming effect is not only dependent on the task, but also the size of the category. Namely, the category needs to be specific enough to be able to focus the sense activation and selection.
CONCLUSION
The current study provides evidence showing that L2 proficiency plays a role in translation priming but that it was not the only factor determining the automatic L1 and L2 lexico-semantic activation patterns of unbalanced bilinguals. Along with previous results, the current data suggest that L2-L1 priming not only depends on the task, but also the size of the category. Our results invite current bilingual models not only to consider L2 proficiency as a predictor, but also language dominance, as well as the conditions under which the L1-L2 representational imbalance is eliminated, as part of the modeling. On the applied side, the current data suggest that L2 processing can be optimized under certain contexts, like in a restricted semantic category.
NOTES
1 This argument will be explained later in the Links model during General Discussion.
2 An important question with regard to how semantic fields are created is critical in this model, but beyond the discussion of this paper. For discussion, see Forster (2006).
Altarriba, J. & Mathis, K. M. (1997). Conceptual and lexical development in second language acquisition.JournalofMemoryandLanguage, 36(4), 550-568.
Balota, D. A. (1994). Visual word recognition: The journey from features to meaning. In M. A. Gernsbacher (Ed.),Handbookofpsycholinguistics(pp. 303-358). San Diego, CA, US: Academic Press.
Baayen, R. H., Piepenbrock, R., & Gulikers, L. (1995).TheCELEXlexicaldatabase(release2) [CD-ROM]. Philadelphia, PA: Linguistic Data Consortium, University of Pennsylvania [Distributor].
Basnight-Brown, D. M. & Altarriba, J. (2007). Differences in semantic and translation priming across languages: The role of language direction and language dominance.Memory&Cognition, 35(5), 953-965.
Brysbaert, M. & Duyck, W. (2010). Is it time to leave behind the Revised Hierarchical Model of bilingual language processing after fifteen years of service?Bilingualism:LanguageandCognition, 13(3), 359-371.
Davis, C., Kim, J., & Sánchez-Casas, R. (2003). In S. Kinoshita & S. J. Lupker (Eds.),Maskedprimingacrosslanguages:Aninsightintobilinguallexicalprocessing. New York, NY, US: Psychology Press.
Davis, C., Sanchez-Casas, R., Garcia-Albea, J. E., Guasch, M., Molero, M., & Ferre, P.(2010). Masked translation priming: Varying language experience and word type with Spanish-English bilinguals.Bilingualism:LanguageandCognition, 13(2), 137-155.de Groot, A. M. & Nas, G. L. (1991). Lexical representation of cognates and noncognates in compound bilinguals.JournalofMemoryandLanguage, 30(1), 90-123.
Dimitropoulou, M., Duabeitia, J.A., & Carreiras, M. (2011a). Masked translation priming effects with low proficient bilinguals.Memory&Cognition, 39(2), 260-275.
Dimitropoulou, M., Duabeitia, J.A., & Carreiras, M. (2011b). Two words, one meaning: evidence of automatic co-activation of translation equivalents.FrontiersinPsychology, 2: 188.
Dunabeitia, J. A., Perea, M., & Carreiras, M. (2010a). Masked translation priming effects with highly proficient simultaneous bilinguals.ExperimentalPsychology, 57(2), 98-107.
Dunn, A. L. & Fox Tree, J. E. (2009). A quick, gradient Bilingual Dominance Scale.Bilingualism:LanguageandCognition, 12(3), 273-289.
Finkbeiner, M., Forster, K., Nicol, J., & Nakamura, K. (2004). The role of polysemy in masked semantic and translation priming.JournalofMemoryandLanguage, 51(1), 1-22.
Forster, K. I. (2004). Category size effects revisited: Frequency and masked priming effects in semantic categorization.BrainandLanguage, 90(1), 276-286.Forster, K. I. (2006). Early activation of category information in visual word recognition.TheMentalLexicon, 1(1), 35-58.
Forster, K. I. & Davis, C. (1984). Repetition priming and frequency attenuation in lexical access.JournalofExperimentalPsychology:Learning,Memory,andCognition, 10, 680-698.
Forster, K. I. & Forster, J. C. (2003). DMDX: A windows display program with millisecond accuracy.BehaviorResearchMethods,INstruments&Computers, 35(1), 116-124.
Forster, K. I. & Hector, J. (2002). Cascaded versus noncascaded models of lexical and semantic processing the turple effect.Memory&Cognition, 30(7), 1106-1116.Forster, K. I. & Jiang, N. (2001). The nature of the bilingual lexicon: Experiments with the masked priming paradigm. In J. L. Nicol (Ed.),Onemind,twolanguages:Bilinguallanguageprocessing(pp. 72-83). Malden, MA, US: Blackwell.Gollan, T. H., Forster, K. I., & Frost, R. (1997). Translation priming with different scripts: Masked priming with cognates and noncognates in hebrew-english bilinguals.JournalofExperimentalPsychology:Learning,Memory, &Cognition, 23, 1122-1139.
Grainger, J. & Frenck-Mestre, C. (1998). Masked priming by translation equivalents in proficient bilinguals.LanguageandCognitiveProcesses, 13(6), 601-623.Hino, Y., Lupker, S. J., & Pexman, P. M. (2002). Ambiguity and synonymy effects in lexical decision, naming, and semantic categorization tasks: Interactions between orthography, phonology, and semantics.JournalofExperimentalPsychology:Learning,Memory,andCognition, 28(4), 686-713.
Jiang, N. (1999). Testing processing explanations for the asymmetry in masked cross-language priming.Bilingualism:LanguageandCognition, 2(1), 59-75.
Jiang, N. & Forster, K. I. (2001). Cross-language priming asymmetries in lexical decision and episodic recognition.JournalofMemoryandLanguage, 44(1), 32-51.
Kinoshita, S. & Lupker, S. J. (Eds). (2003).Maskedpriming:Stateoftheart. Hove: Psychology Press.
Kroll, J. F., Michael, E., Tokowicz, N., & Dufour, R. (2002). The development of lexical fluency in a second language.SecondLanguageResearch, 18, 137-171.
Kroll, J. F. & Stewart, E. (1994). Category interference in translation and picture naming: Evidence for asymmetric connection between bilingual memory representations.JournalofMemoryandLanguage, 33(2), 149-174.
Kroll, J. F. & Tokowicz, N. (2005). In J. F. Kroll & A. M. B. De Groot (Eds.),Modelsofbilingualrepresentationandprocessing:Lookingbackandtothefuture(pp. 531-552). New York: Oxford University Press.Lee, W. L., Wee, G., Tzeng, O. J., & Hung, D. L. (1992). A study of interlingual and intralingual Stroop effect in three different scripts: Logograph, syllable, and alphabet. In R. J. Harris (Ed.),Cognitiveprocessinginbilinguals(pp. 427-442). Amsterdam: Elsevier.
Neely, James H. (1991). Semantic priming effects in visual word recognition: A selective review of current findings and theories.BasicProcessesinReading:VisualWordRecognition, 11, 264-336.Neely, James H. (1977). Semantic priming and retrieval from lexical memory: Roles of inhibitionless spreading activation and limited-capacity attention.JournalofExperimentalPsychology:General, 106(3), 226.
Perea, M., Dunabeitia, J. A., & Carreiras, M. (2008). Masked associate/semantic priming effects across languages with highly proficient bilinguals.JournalofMemoryandLanguage, 58(4), 916-930.Pexman, P. M., Hino, Y., & Lupker, S. J. (2004). Semantic ambiguity and the process of generating meaning from print.JournalofExperimentalPsychology:Learning,Memory,andCognition, 30(6), 1252-1270.Posner, MI & Snyder, CRR. (1975). Facilitation and inhibition in the processing of signals.AttentionandPerformance, 5, 669-682.
Sánchez-Casas, R. M., Davis, C. W., & García-Albea, J. E. (1992). Bilingual lexical processing: Exploring the cognate/non-cognate distinction.EuropeanJournalofCognitivePsychology, 4(4), 293-310.
Stefani, L. (1994). Peer, self and tutor assessment: Relative reliabilities.StudiesinHigherEducation, 19, 69-75.
Schoonbaert, S., Duyck, W., Brysbaert, M., & Hartsuiker, R. J. (2009). Semantic and translation priming from a first language to a second and back: Making sense of the findings.Memory&Cognition, 37(5), 569-586.
Tzelgov, J., Henik, A., & Leiser, D. (1990). Controlling Stroop interference: Evidence from a bilingual task.JournalofExperimentalPsychology-LearningMemoryandCognition, 16(5), 760-771.
Wang, X. (2010). The bilingual lexicon: Models and implications. In R. K. Mishra & N. Srinivasan (Eds.).Languageandcognitioninterface:Stateoftheart. Publisher: LINCOM Europa.
Wang, X. (2013). Language dominance in translation priming: Evidence from balanced and unbalanced Chinese-English bilinguals.QuarterlyJournalofExperimentalPsychology, 66(4), 727-43.Wang, X. & Forster, K. I. (2010). Masked translation priming in semantic categorization: Testing the sense model.Bilingualism:LanguageandCognition, 13(3), 327-340.
Wang, X. & Forster, K. I. (in press). Is translation priming asymmetry due to partial awareness of the prime?Bilingualism:LanguageandCognition.
Witzel, Naoko Ouchi, & Forster, Kenneth I. (2012). How L2 words are stored: The episodic L2 hypothesis.JournalofExperimentalPsychology:Learning,Memory,andCognition, 38(6), 1608.
Xia, V. & Andrews, S. (2014). Masked translation priming asymmetry in Chinese-English bilinguals: making sense of the Sense Model.TheQuarterlyJournalofExperimentalPsychology.
10.3969/j.issn.1674-8921.2014.12.006
Correspondence should be addressed to Dr. Xin Wang, 15 Norham Gardens, Oxford University, Oxford, OX2 6PY, UK. Email: xin.wang@education.ox.ac.uk; xinwang267@gmail.comassociation/link
猜你喜歡
作文小學中年級(2023年2期)2023-02-09
瘋狂英語·新讀寫(2022年5期)2022-04-29
小太陽畫報(2020年10期)2020-10-30
學苑創(chuàng)造·A版(2020年5期)2020-07-04
幼兒智力世界(2019年9期)2019-12-10
娃娃樂園·3-7歲綜合智能(2016年4期)2016-10-24
學苑創(chuàng)造·A版(2016年6期)2016-06-20
小學閱讀指南·低年級版(2014年10期)2015-01-27
中國火炬(2014年3期)2014-07-24
延河(下半月)(2014年2期)2014-02-28

- 當代外語研究的其它文章
- Call For Papers
- Language Learning Strategies in China: A Call for Teacher-friendlyResearch
- A Meta-analysis of Cross-linguistic Syntactic Priming Effects
- Effects of Explicit Focus on Form on L2 Acquisition of EnglishPassive Construction
- Development of Implicit and Explicit Knowledge of GrammaticalStructures in Chinese EFL Learners
- Extending the Distributional Bias Hypothesis to the Acquisition ofHonorific Morphology in L2 Korean