
Establishment of a diagnostic model of coronary heart disease in elderly patients with diabetes mellitus based on machine learning algorithms
2022-07-13 01:58:40HuXUWenZheCAOYongYiBAIJingDONGHeBinCHEPoBAIJianDongWANGFengCAO1LiFAN1
Journal of Geriatric Cardiology 2022年6期
Hu XU, Wen-Zhe CAO, Yong-Yi BAI, Jing DONG, He-Bin CHE, Po BAI, Jian-Dong WANG?, Feng CAO1,,?, Li FAN1,,?
1. Chinese PLA Medical School, Chinese PLA General Hospital, Beijing, China; 2. Department of Cardiology, the Second Medical Center, National Clinical Research Center for Geriatric Diseases, Chinese PLA General Hospital, Beijing, China;3. Department of General Surgery, the First Medical Center, Chinese PLA General Hospital, Beijing, China; 4. Institute of Geriatrics, the Second Medical Center, Chinese PLA General Hospital, Beijing, China; 5. Medical Big Data Research Center &National Engineering Laboratory for Medical Big Data Application Technology, Chinese PLA General Hospital, Beijing, China;6. Department of Respiratory Diseases, Chinese PLA Rocket Force Characteristic Medical Center, Beijing, China
ABSTRACT
With the population in China ageing at an increasing rate, the phenomenon of comorbidity among the elderly has become increasingly prominent. Comorbidity is the coexistence of two or more chronic diseases or conditions.[1]The prevalence of comorbidity in individuals aged 65 years or older is 76.6%.[2]Comorbidity has brought a heavy burden to individuals, families and society. In the elderly, comorbidity with coronary heart disease (CHD) and diabetes mellitus(DM) is one of the most common occurrences. There are 114 million patients with DM in China, which is more than any other country in the world.[3]Cardiovascular disease, which is represented by CHD, is the leading cause of death among urban and rural residents. It is estimated that there are 11.39 million patients with CHD in China.[4]In patients with DM,the risk of CHD increased significantly.[5,6]DM is an independent risk factor for CHD.[7]CHD is one of the most common complications of DM.[8]The life expectancy of patients with DM complicated with cardiovascular disease is significantly decreased.[9]
In elderly patients with comorbid CHD and DM,the symptoms of myocardial ischaemia are relatively mild or absent, which is not easy to determine and diagnose.[10]Irreversible pathological damage is often present when the diagnosis of CHD is confirmed, which seriously affects the quality of life of patients.[11]Coronary angiography is the gold standard for diagnosing of CHD. However, this operation is complex, invasive and expensive, and is not included in routine examinations. Therefore, early screening of CHD in elderly patients with DM is of great significance.
In recent years, many experts and researchers have begun to explore new models of DM diagnosis, making full use of medical big data and machine learning (ML) algorithms, and have achieved good results in prediction and diagnosis of CHD.[12-15]For different data sets, researchers use different algorithms,such as sequential minimal optimization,[16]artificial neural network[17]and neural network models,[18-20]to build CHD diagnosis models, including a variety of features, like electrocardiogram (ECG),[21]heart rate variability,[22]and even facial photos.[23]Currently,there is no specific model to predict the risk of CHD in elderly patients with DM. This study aimed to establish a prediction model of CHD in elderly patients with DM using the ML algorithm, and to provide a new auxiliary screening method from the perspective of medicine and big data science.
METHODS
Study Population
Based on Medical Big Data Research Center of Chinese PLA General Hospital in Beijing, China, we identified a total of 28,059 elderly inpatients (≥ 60 years) who were diagnosed with DM from January 2008 to December 2017. The inclusion criteria were inpatients aged 60 years or older and the discharge diagnosis included DM according to the corresponding diagnostic criteria. The exclusion criteria were malignant tumor, severe hepatic and renal dysfunction, respiratory failure, sepsis, shock, severe autoimmsune disease, severe hematological disease, acute rheumatic fever, chronic rheumatic valvular disease,myocarditis, and myocardiopathy. The diagnostic criteria for CHD are based on the European Society of Cardiology guidelines for the diagnosis and management of chronic coronary syndromes.[24]This study was approved by the Ethics Committee of Chinese PLA General Hospital (No.S2018-269-02).
According to the inclusion and exclusion criteria,4892 patients were excluded. Finally, a total of 23,167 elderly patients with DM were included in the present study. Among them, 10,533 patients complicated with CHD were included in the research group and 12,634 patients complicated without CHD were included in the control group.
To further validate the performance of the models, we collected information on 7447 elderly patients with DM admitted from January 2018 to December 2019. Of these patients, there were 3116 patients with CHD and 4331 patients without CHD.
Candidate Variables
All demographic characteristics, laboratory examinations, history of complications and other clinical data were used to establish prediction models. For missing data, the nonparametric filling missForest algorithm was used. Any variable with > 30% of missing data was removed. Recursive feature elimination (RFE) is a method for feature selection that combines with various ML models to eliminate redundant information, thus identifying the most influential features for each model. In our study, RFE was used to rank the importance of all 67 feature variables, and the top 15 feature variables were selected to construct models. The importance of each variable in each model was also evaluated.
Model Development
To develop ML models, random split validation was used. We selected 80% of the research group samples and 80% of the control group samples as the training dataset. The remaining subset (20%) was reserved as the testing dataset.
Five commonly used ML algorithms were used to train the models and diagnose CHD in elderly patients with DM. Extreme gradient boosting (XGBoost) is an ensemble ML algorithm based on decision tree (DT). Random forest (RF) is a combined classifier composed of multiple DTs, and it is an excellent ensemble learning method. DT is a ML algorithm that continuously introduces features to reduce the uncertainty of original random variables.Adaptive boosting (Adaboost) is an algorithm that integrates the weak classifiers to form a strong classifier with excellent performance. Logistic regression (LR) is a probabilistic nonlinear regression model, which is a multivariate analysis method to study binary output classification.[25,26]Various Python packages were used to conduct this analysis.
Model Performance
The performance of the model was evaluated using the standard format, namely confusion matrix.[27]The evaluation indicators included sensitivity, specificity, accuracy, precision, F1-score, receiver operating characteristic curves, and area under the curve(AUC). By comparing the relevant parameters of various models, the optimal classification model was found out.
Statistical Analysis
Continuous variables were presented as mean ±SD or median (interquartile range) and categorical variables were presented as counts (percentages).The Mann-WhitneyUtest and the Pearson’s chi-squared test were used to test the difference of variables between the research group and the control group. Different Python packages were used to establish the five ML models. DeLong method was used to compare AUC between different models, which was realized by MedCalc 11.4.2.0 (MedCalc Software,Ostend, Belgium). Two-sidedP-value < 0.05 were considered statistically significant. Statistical analysis was performed with SPSS 24.0 (SPSS Inc., IBM,Armonk, NY, USA) and Python 3.7.0 (https://www.python.org/downloads/release/python-370/).
RESULTS
Clinical Characteristics
A cohort of 23,167 elderly patients with DM was enrolled in our study, including 10,533 patients in the research group and 12,634 patients in the control group. We collected demographic characteristics, laboratory examinations, and history of complications. The clinical characteristics of all patients are summarized in Table 1.
Predictor Variables
RFE was used to rank the importance of all 67 feature variables, and the top 15 feature variables were selected to construct models. The top 15 feature variables were pro-B-type natriuretic peptide, hemoglobin A1c, troponin T, high-density lipoprotein cholesterol, total bile acid, D-dimer, glycated serum pr-otein, activated partial thromboplastin time, triglyceride, low-density lipoprotein cholesterol, total cholesterol, total protein, creatine kinase, creatine kinase-MB and lymphocyte.dels, XGBoost performed the best with the highest AUC. The AUC is 0.851 (95% CI: 0.841-0.861). The importance scores of the 15 features of XGBoost are shown in Figure 2.
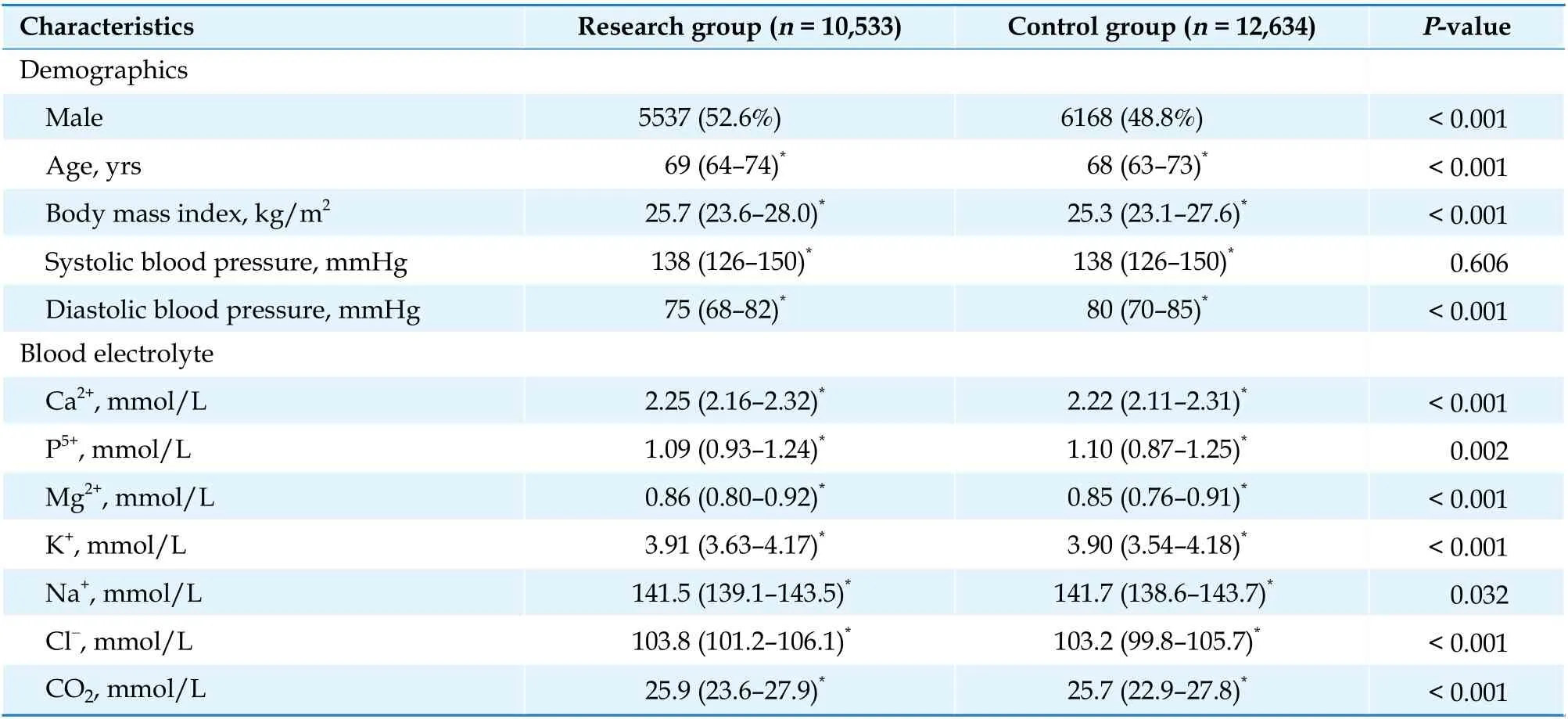
Table 1 Clinical characteristics of all patients.
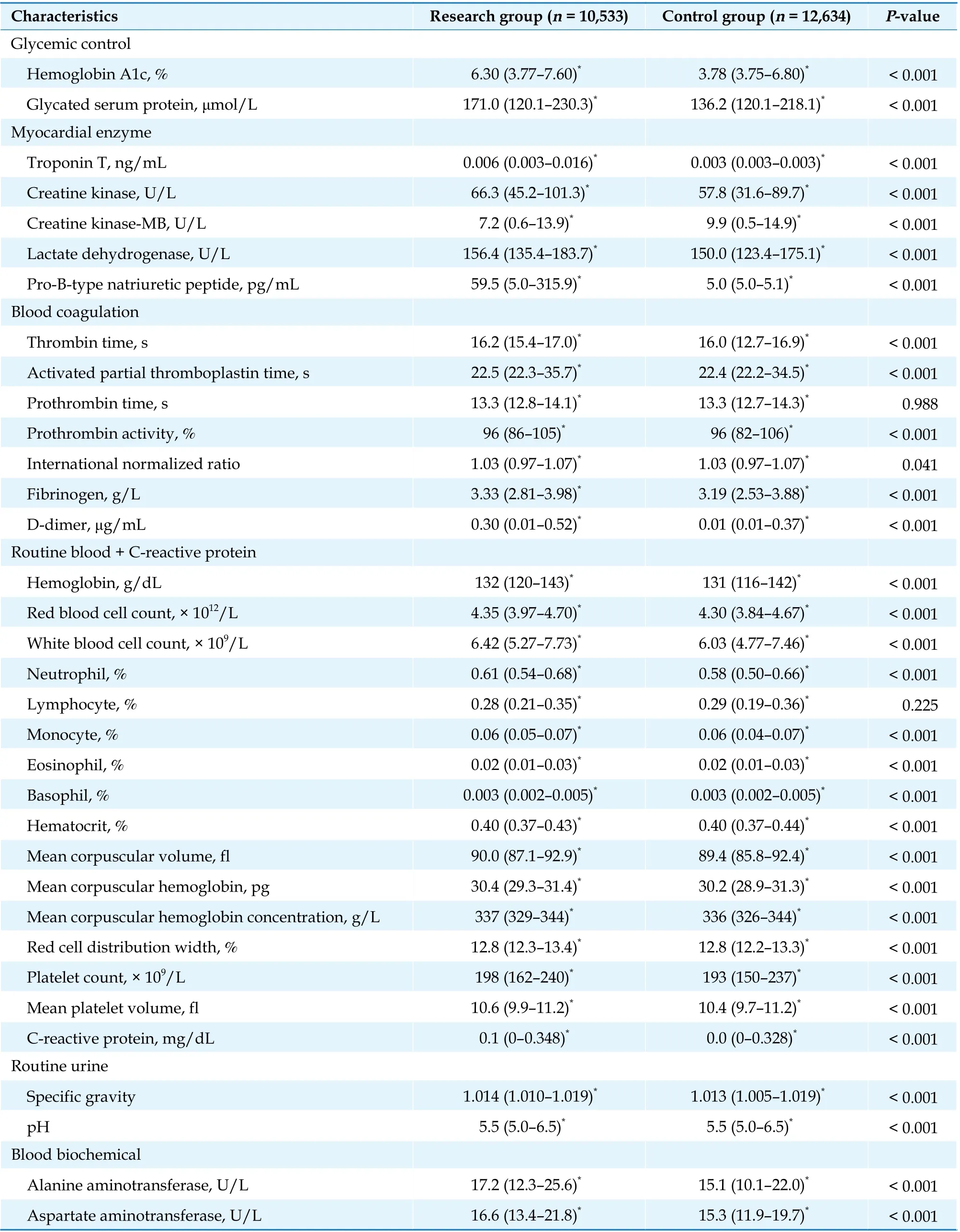
Continued
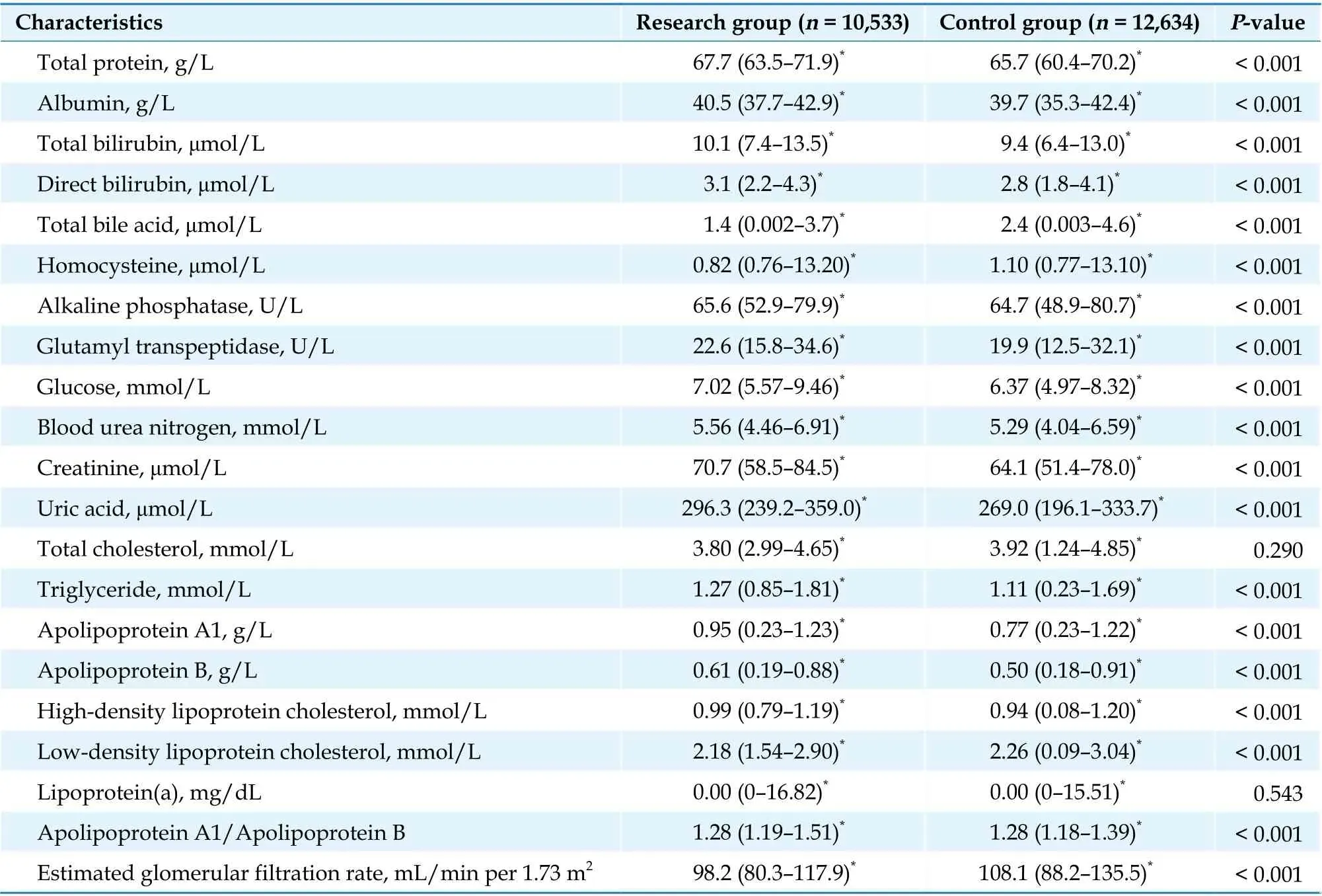
Continued
Performance of the Predictive Models on Test set
The classification precision in test set of XGBoost,RF, DT, Adaboost and LR models was 0.778, 0.789,0.753, 0.750 and 0.689, respectively; and the AUC of the subjects was 0.851, 0.845, 0.823, 0.833 and 0.731,respectively (Table 2, Figure 1). Among the five mo-
Performance of the XGBoost Model on a Newly Recruited Independent set
The clinical characteristics of newly recruited subjects are shown in Table 3. Applying the XGBoost model with optimal performance to a newly recru-ited independent dataset for validation, the diagnostic sensitivity, specificity, precision, and AUC were 0.792, 0.808, 0.748 and 0.880, respectively (Table 4,Figure 3). The XGBoost model performed well in diagnosing CHD in elderly patients with DM.

Table 2 Performance of the five models on the testing sets.
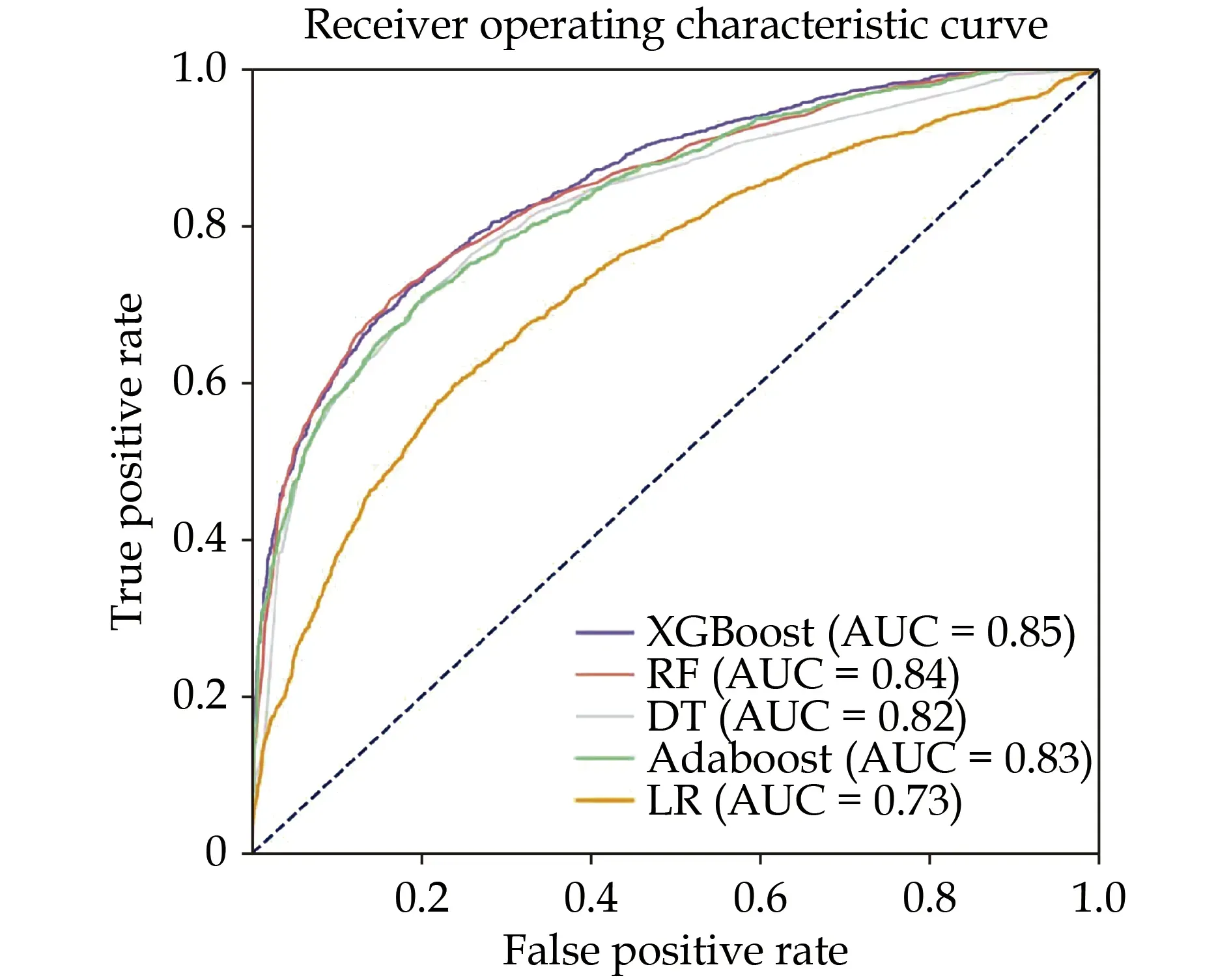
Figure 1 The receiver operating characteristic and the AUC of the five prediction models on the testing dataset. Adaboost: adaptive boosting; AUC: area under the curve; DT: decision tree; LR:logistic regression; RF: random forest; XGBoost: extreme gradient boosting.
DISCUSSION
Based on data from the Medical Big Data Research Centre of Chinese PLA General Hospital in Beijing,China, the present study collected hospitalization information for tens of thousands of elderly patients with DM in the past ten years. Five ML algorithms were used to build a diagnostic model of CHD in elderly patients with DM. Ultimately, it was found that the XGBoost model best distinguished patients with CHD and had good performance.
Based on ML algorithms, researchers explored the diagnosis of CHD.[28]A review published in 2019 studied 149 research articles related to ML-based CHD detection.[29]The 67 relevant datasets came from 18 countries and regions of three continents. The sample size ranged from 20 to 240,000, and the median sample size was approximately 350. Similar to our study, Fan,et al.[30]trained an artificial intelligence model using RF to predict CHD risk among patients with DM, there were 1273 patients enrolled in the study. Researchers selected the top eight features (age, heart rate, diastolic blood pressure, blood platelet, low-density lipoprotein cholesterol, total cholesterol level, course of hypertension and course of DM) from the total 50 features to develop the model.The model achieved an AUC of 0.77 on the training dataset and 0.80 on the testing dataset. In our study,a dataset of 28,059 elderly patients with DM was constructed. Our research sample size is large, and the performance of the model is better. The results in different studies cannot be generalized due to the differences in the analyzed datasets, sample sizes, features, data collection areas, performance metrics,and applied ML algorithms.

Figure 2 Ranking of the relative importance of XGBoost model features. XGBoost: extreme gradient boosting.
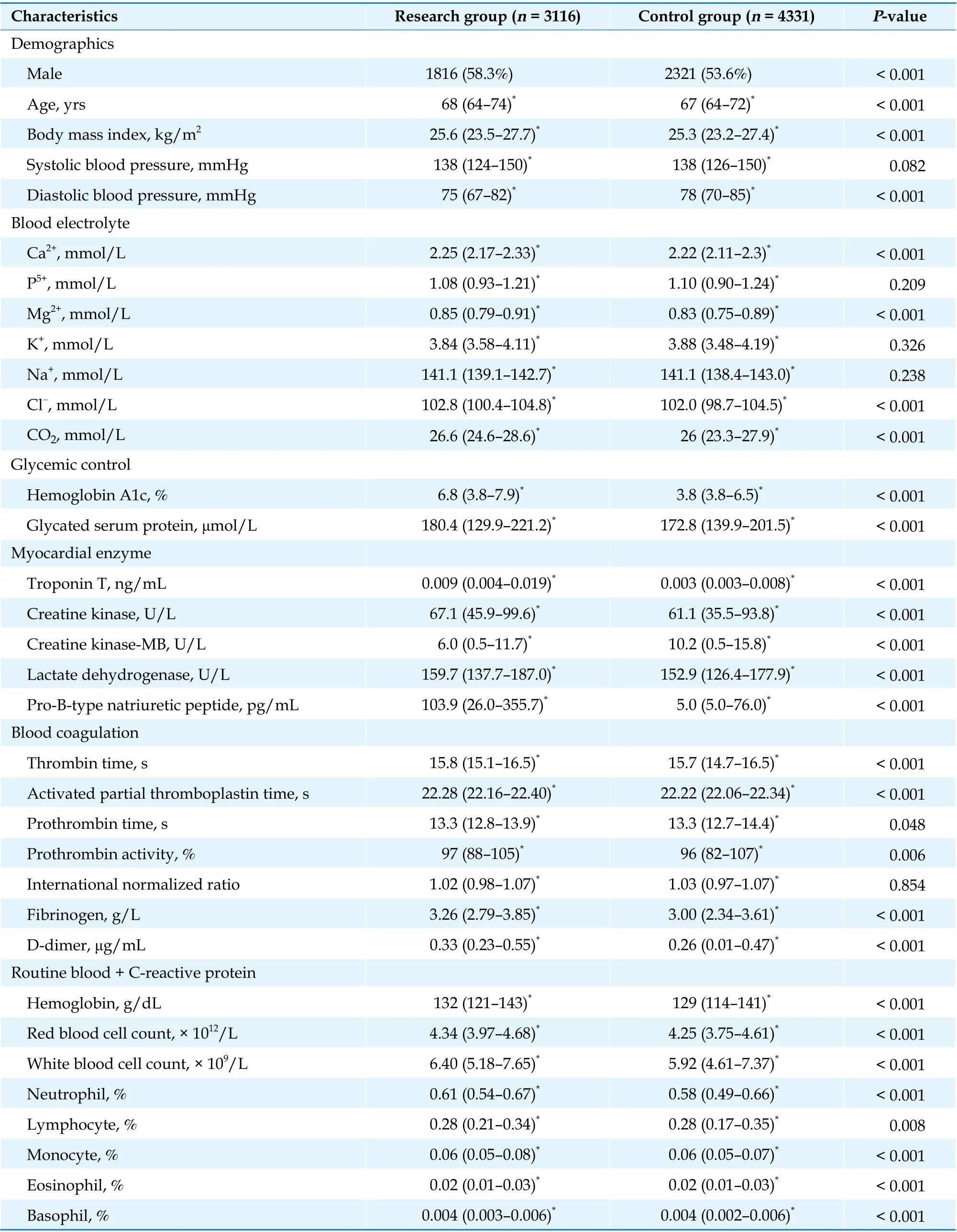
Table 3 Clinical characteristics of newly recruited subjects.
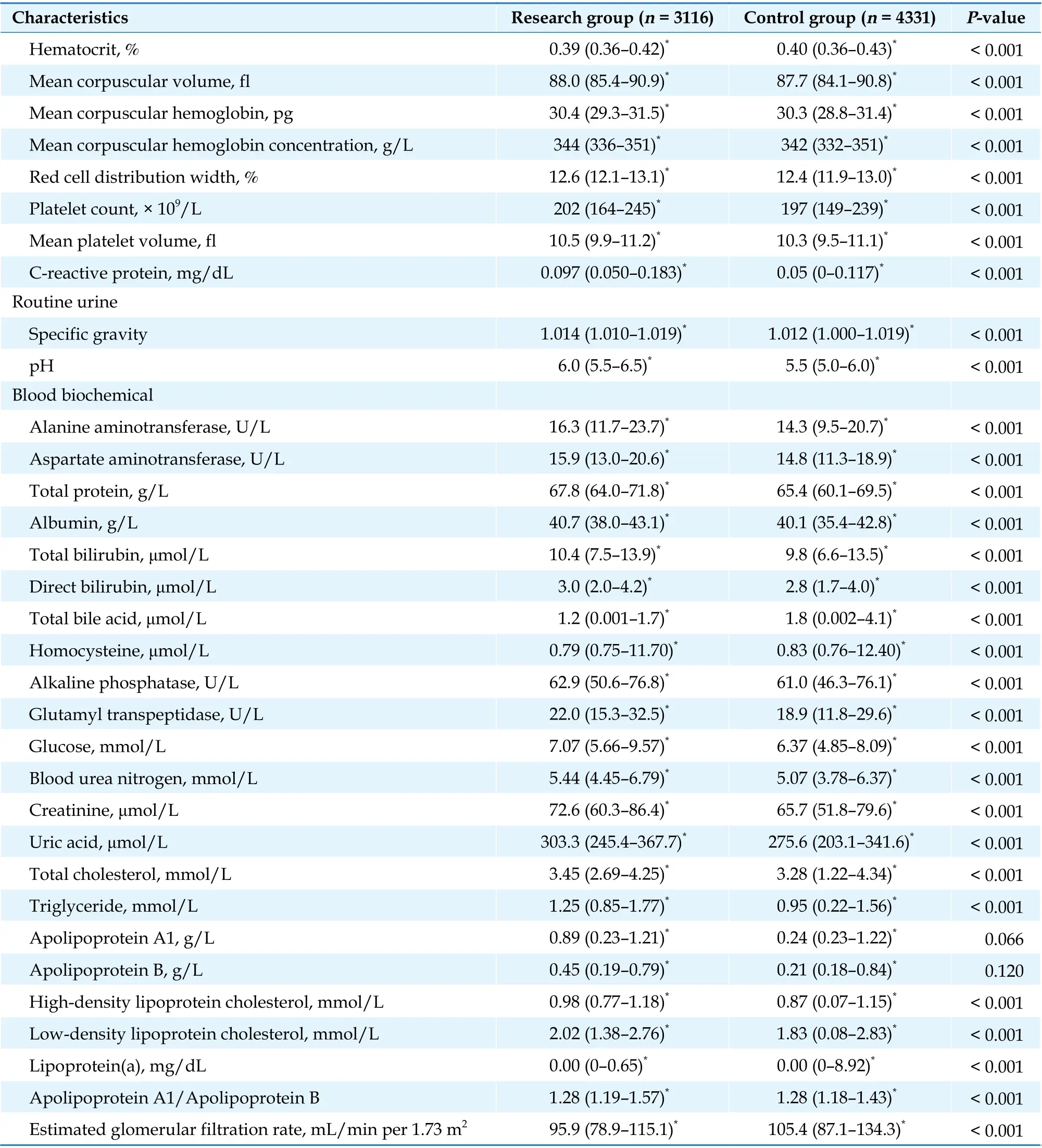
Continued
Feature selection (selecting subsets of relevant features for model development) has a significant impact on the model performance.[25]Many feature selection methods have been used for model creation,including information gain, correlation, principal component analysis, Gini index and the genetic algorithm.[29]In our study, we applied RFE as a filter for muting irrelevant features in the process of feature selection. RFE was a feature selection method that trained a model and removed the weakest feature(or features) until a specified number of features were reached. The features were sorted by feature_importances_attributes of the model. In contrast to other methods, RFE took the final desired number of features to use as input, and then recursively reduced the number of features to use that attemptsto eliminate dependencies and collinearity that may exist in the model.

Table 4 Performance of the five models on the validation sets.
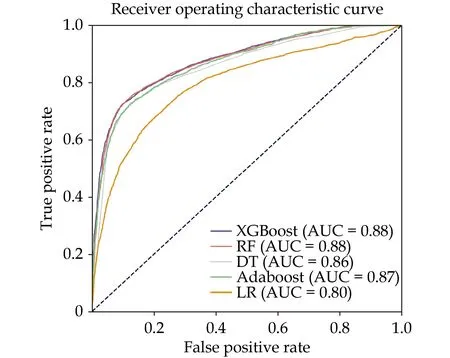
Figure 3 The receiver operating characteristic and the AUC of the five prediction models on the newly recruited dataset. Adaboost: adaptive boosting; AUC: area under the curve; DT: decision tree; LR: logistic regression; RF: random forest; XGBoost: extreme gradient boosting.
A variety of feature categories were used to detect CHD. Some datasets only contain ECG features,[21,31]while others contain demographic, laboratory, symptom and examination, fluoroscopy and echo features.[32]In most CHD datasets, demographic features were widely used, such as age and sex.Other features, such as genetic features, were seldom used. Most datasets only show whether the patients have CHD. Few of them contain information on the stenosis severities of the three main arteries of the heart, which is the main limitation of these datasets. In our study, the variables included in the screening were mostly demographic and laboratory examinations. Compared to other categories of features, it is much easier to collect data that belong to these categories. Unfortunately, with the ML method, we have not found a new specific index that can well identify CHD in elderly patients with DM. However, we still believe that the auxiliary diagnosis system based on such research will effectively serve the clinic in the future and play a positive role in the screening, early warning and early diagnosis of CHD in elderly patients with DM.
Among the five models, RF, Adaboost and XGBoost showed better prediction performance. The RF algorithm performed random sampling, and the trained model had small variance and strong generalization ability, but on a sample set with relatively large noise, the RF model was prone to overfitting.Adaboost had high accuracy and fully considered the weight of each classifier, however, when the data was unbalanced, it would lead to a decrease in the classification accuracy of the model. XGBoost added a regular term to the objective function to control the complexity of the model and made the learned model simpler. XGBoost drew on the practice of RF and supported column sampling, which could not only reduce overfitting, but also reduced the workload of calculation. The above three ML algorithms used in this study minimized error and improved prediction accuracy, and identified other latent variables that were not easily observed, but the “black box”characteristics of these models were more difficult to explain, that is, they could not explain the inherent complexity of how risk factor variables interact and their independent effects on outcomes. In the testing sets, the sensitivity of the XGBoost model was not ideal (0.690). However, in the validation sets, the sensitivity was 0.792, which reflected that the XGBoost model had good transportability and generalizability. In the future, we will incorporate richer features and try more algorithms to further improve the performance of the model.
STRENGTHS AND LIMITATIONS
The strengths of this study are in the specific study population, large sample size, and multiple ML models. We collected the hospitalization information of tens of thousands of elderly patients with DM from the past ten years. We used five ML algorithms to establish models. Their performance was assessed with external validation by thousands of patients. We also obtained a prediction model for CHD in elderly patients with DM. However, there were some limitations that must be noted. Firstly, the variables included in the screening were mostly laboratory examinations. The inclusion of symptoms, new biomarkers, environmental factors, ECGs, cardiac ultrasounds and other data may further improve the prediction efficiency of the model. Secondly, doctors may miss diagnosis when writing medical records, which is also the limitation of this study based on medical records. Last but not least, the datasets for training and validation were from the same hospital. If the research is conducted in multiple centres, models would be more substantial and robust. Using larger datasets, more features and ML approaches may achieve better results.
CONCLUSIONS
In summary, this study established a ML model to predict CHD in elderly patients with DM, which may provide a reference for the early detection and intervention of CHD in elderly patients with DM.
ACKNOWLEDGMENTS
This study was supported by the Key Project of Chinese Military Health Care Projects (No.18BJZ32), the Projects of International Cooperation and Exchanges NSFC (No.81820108019), the Technical Fund for the Foundation Strengthening Program of China (2021-JCJG-JJ-1079), the Chinese Military Innovation Project (CX19028), and the Project of National Clinical Research Center for Geriatric Disease (NCRCG-PLAGH-2019024). All authors had no conflicts of interest to disclose.
 Journal of Geriatric Cardiology2022年6期
Journal of Geriatric Cardiology2022年6期
- Journal of Geriatric Cardiology的其它文章
- Transplant-associated thrombotic microangiopathy: a rare but deadly complication post orthotopic heart transplantation
- Prognostic significance of multiple triglycerides-derived metabolic indices in patients with acute coronary syndrome
- Simultaneous interventional therapy for coarctation of the aorta combined with intracristal ventricular septal defect in older age adult
- Acute myocardial infarction complicated with takotsubo syndrome in an elderly patient: case report and literature review
- Normalizing the dementia status in cardiovascular diseases:a perspective
- Efficacy of comprehensive remote ischemic conditioning in elderly patients with acute ST-segment elevation myocardial infarction underwent primary percutaneous coronary intervention