
Parallel Processing Design for LTE PUSCH Demodulation and Decoding Based on Multi-Core Processor
2009-06-04 13:08:10ZhangZiranLiranLiJunLiChangXiao
ZTE Communications 2009年1期
Zhang Ziran,Liran,Li Jun,Li ChangXiao
(ZTE Corporation, Shenzhen 518057, P. R. China)
Abstract:The Long Term Evo lution(LTE)system im poses high requirem ents for d ispatching delay.Moreover,very large air interface rate of LTE requires good p rocessing capab ility for the devices p rocessing the baseband signals.Consequently,the sing le-core p rocessor cannotmeet the requirem ents o f LTE system.This paper analyzes how to use m ulti-core p rocessors to achieve parallel p rocessing o f up link demodu lation and decod ing in LTE systems and designs an app roach to parallel p rocessing.The test results p rove that this app roach works quite well.
L ong Term Evolution(LTE)refers to the long term evolution of3G system s.Accord ing to LTE p rotocols,the up link Hyb rid Automatic Repeat-Request(HARQ)delay,from the time eNodeB finishes receiving PhysicalUp link Shared Channel(PUSCH)sub frames to the time the Acknow ledge(ACK)or Non-Acknow ledge(NACK)message is sentvia the downlink,should be nomore than 3m s.In order to verify such delay in case ofsing le-core p rocessor,tests have been conducted under the follow ing cond itions:sing le core p rocessors are used to p rocess demodulation and decod ing serially on the up link,the User Equipment(UE)type is category 5,the TransportBlock(TB)size is 75,056 bits,virtualMultip le-Input Multip le-Output(MIMO)is used on the up link and the rate at the air interface reaches 150Mb/s.The test results show that the totalp rocessing delay cannot meet the requirements specified in the p rotocol.As a result,multi-core p rocessors are introduced to perform demodulation and decoding parallelly on the up link so as to shorten the p rocessing time,allow ing the delay to meet them inimum requirementof the p rotocol,i.e.3m s.[1-6]
1 Architecture and Principle of Multi-Core Processor
1.1 Architecture
Multi-core p rocessor technology is a new technology recently introduced in CentralProcessing Unit(CPU)design.It allows two ormore p rocessor cores integ rated onto one chip to enhance the p rocessing capability of the chip.
In this paper,we take examp le of three-core p rocessor,i.e.three cores integ rated onto one chip.The three cores,called Core0,Core1and Core2respectively,share thememory and other peripheraldevices,and each of them is configured w ith a high-speed L2 cache to decrease the bottleneck effectwhich may occurwhen the three cores access thememory at the same time.Any shared resource(e.g.a segmentof codes or data in Doub le Data Rate Two(DDR2))can be shared orexc luded via semaphores.Allcores run theirown Real-Time Operating Systems(RTOSs)and communicatew ith each other through semaphores.A task on a core can communicate w ith another task on the same core.Hence,specific app lications are realized w ith this cooperative communication between tasks.By d ividing an app lication into severaltasks thatcan run parallelly on differentcores,the data can be p rocessed simultaneously,thus the system's p rocessing capability is enhanced.
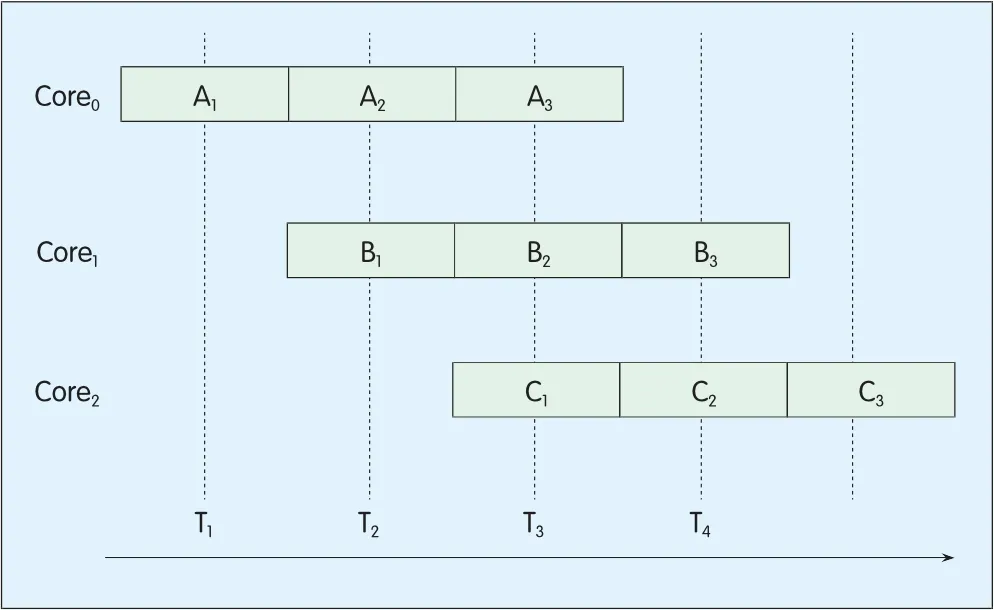
?Figure 1.Assembly line processing of multi-core processor.

?Figure 2.Distributed processing of multi-core processor.
1.2 Principle of Parallel Processing of Multi-Core Processor
A criticalissue in app lying multi-core technology is how to convert the serial p rocessing ofa sing le-core p rocessor into the parallelp rocessing ofa multi-core p rocessor.Suppose a serial p rocessing task involves threemodules A,B and C,and theirp rocessing times are T1,T2and T3respectively.Itcan achieve parallelp rocessing w ith a multi-core p rocessor in one of the follow ing two ways.
1.2.1 Assemb ly Line Processing
The firstway is called assemb ly line p rocessing,w ith which the tasks of three modules A,B and C are p rocessed by Core0,Core1and Core2respectively.
The assemb ly line p rocessing goes as follows:First,divide eachmodule into three sub-p rocesses respectively.That is to say,d ividemodule A into A1,A2and A3,module B into B1,B2and B3,and module C into C1,C2and C3.Aftera sub-p rocess ofmodule A is com p leted,itwillbe sent tomodule B forp rocessing;sim ilarly,aftera sub-p rocess of module B is com p leted,itw illbe sent to module C forp rocessing,thus all sub-p rocesses are p rocessed in an assemb ly line way,as shown in Figure 1.The core in the reardoes nothave to wait forallsub-p rocesses of the core in front of it to com p lete before itbegins p rocessing;instead,after the core in the frontcom p letes a sub-p rocess,itgives the sub-p rocess to the one behind it for p rocessing.In this way,parallel p rocessing is realized.
1.2.2Distributed Processing
In the d istributed p rocessingmethod,each core p rocessesmodule A,B and C simultaneously.Fora UE,ifa sing le-core p rocessor canmeet the delay requirement for p rocessing module A,B or C,a three-core p rocessor(i.e.Core0,Core1and Core2)can be used to p rocess the threemodules in a d istributed way.As each core p rocessesmodule A,B and C parallelly,more than one UE can be distributed on d ifferentcores for load sharing,thus parallelp rocessing is achieved.The p rocessing is illustrated in Figure 2.
The d ifference between Figure 2(a)and(b)is as follows:In 2(a),module B has to wait forp rocessing untilall sub-p rocesses ofmodule A are comp leted;while in 2(b),module A and B can be p rocessed at the same time.

▲Figure 3. Processing of PUSCH.
2 Analysis and Design of Parallel Processing of LTE PUSCH Based on Multi-Core Processor
2.1 PUSCH Overview
PUSCH is used to transm itservice data.It is shared bymultip le UEs and d ispatched w ith Media Access Control(MAC)d ispatcher.
At the UE side,the p rocessing of PUSCH is illustrated in Figure 3.
The demodulation and decoding flowchartofPUSCH is shown in Figure 4.
2.2 System Delay Requirement
2.2.1 Delay Requirement for Up link HARQ in LTESystem
Them inimum delay requirement for up link HARQ in LTE systems is 3m s.The delay refers to the duration when eNodeB begins to p rocess data packets received from Up link Shared Channel(UL-SCH)and responds w ith ACK orNACK message via the air interface.The p rocessing ateNodeB inc ludes channel estimation,MIMO decod ing,Inverse Disc rete Fourier Transform(IDFT),demodulation and decoding.

▲Figure 4. Demodulation and decoding flowchart of PUSCH.
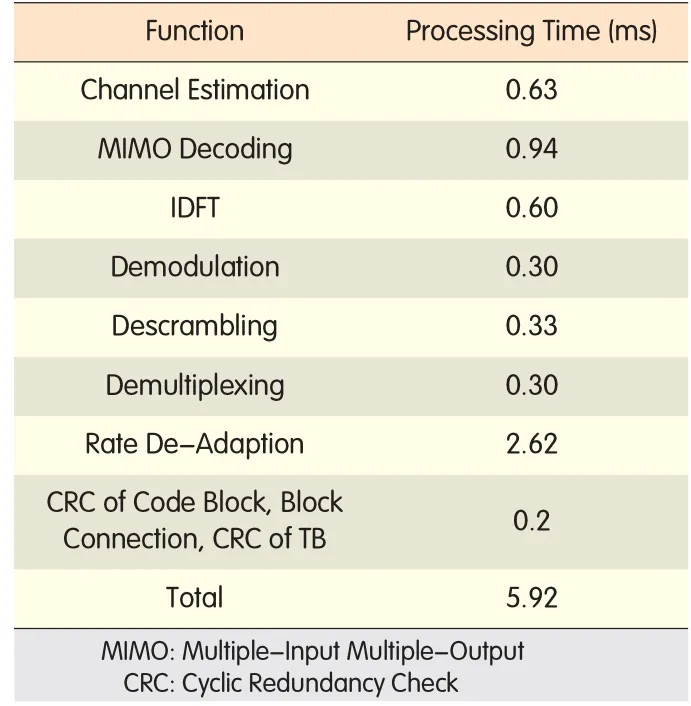
▼Table 1. Processing time of single-core processor
2.2.2 Delay TestBased on Sing le-Core Processor
The delay testofa sing le-core p rocessor(CPU frequency:1GHz)is conducted under the follow ing cond itions:a cellwith 20MHz bandw id th,1,200 sub-carriers,4 receiving antennas ateNodeB side,2 transm itting antennas atUEside,virtual MIMO forup link receiving,2 code words,TB size of75,056 bits,64Quad rature Amp litude Modulation(64QAM)scheme,and a peak rate of150Mb/s.The test
results are listed in Tab le 1,which show the totalp rocessing time of5.92m s,more than the given 3ms.Therefore,the sing le-core p rocessor cannotmeet the system's delay requirement.
2.3 Feasibility Analysis of Parallel Processing
With amulti-core p rocessor,parallel p rocessing can be achieved.The feasibility ofparallelp rocessing is analyzed as follows:·Demodulation:This p rocess can be d ivided among multip le cores based on modulation symbols and every core needs to generate the entire scramb ling sequence.Therefore,the cores can start demodulation before getting all modulation symbols.
·Descramb ling:This p rocess can be d ivided among multip le cores by softbit.Hence,itcan startbefore allsoftbits are given.Each coremustgenerate the entire scramb ling sequence.
·Controland data demultip lexing:This p rocess can only be d ivided among multip le cores by the user.Various users'demultip lexing tasks can be p rocessed by d ifferentcores.As it is quite com p licate to d ivide the demultip lexing task ofa useramong multip le cores and deinterleaving of d ifferentSing le Carrier Frequency Division Multip le Access(SC-FDMA)symbols w ithin a Transm ission Time Interval(TTI)is involved,the demultip lexing p rocess cannotbegin untilallsymbols ofa TTIare collec ted.
·Rate de-adap tion:This p rocess can be d ivided among multip le cores by code b lock.Thatis to say,the code b locks ofdifferentusers can be p rocessed by d ifferentcores,and the code b locks ofa user can also be p rocessed by d ifferentcores.
·CRC of code b lock:This p rocess can be divided among multip le cores by code b lock.That is to say,the code b locks ofdifferentusers can be p rocessed by d ifferentcores,and the code b locks ofa user can also be p rocessed by d ifferentcores.Once a code b lock rather than allcode b locks is decoded,the CRC check can be performed for the decoded b lock.
·Code b lock connection:This p rocess can only be d ivided among multip le cores by the user.The task of one user can only be p rocessed by one core.Once a code b lock rather than all code b locks is decoded,this p rocess can be performed for the decoded b lock.
·CRC of TB:This p rocess can only be divided amongmultip le cores by the user.The task ofone user can only be p rocessed by one core.Itcan startonly afterallTBs are decoded.
2.4 Design of Parallel Processing Based on Multi-Core Processor
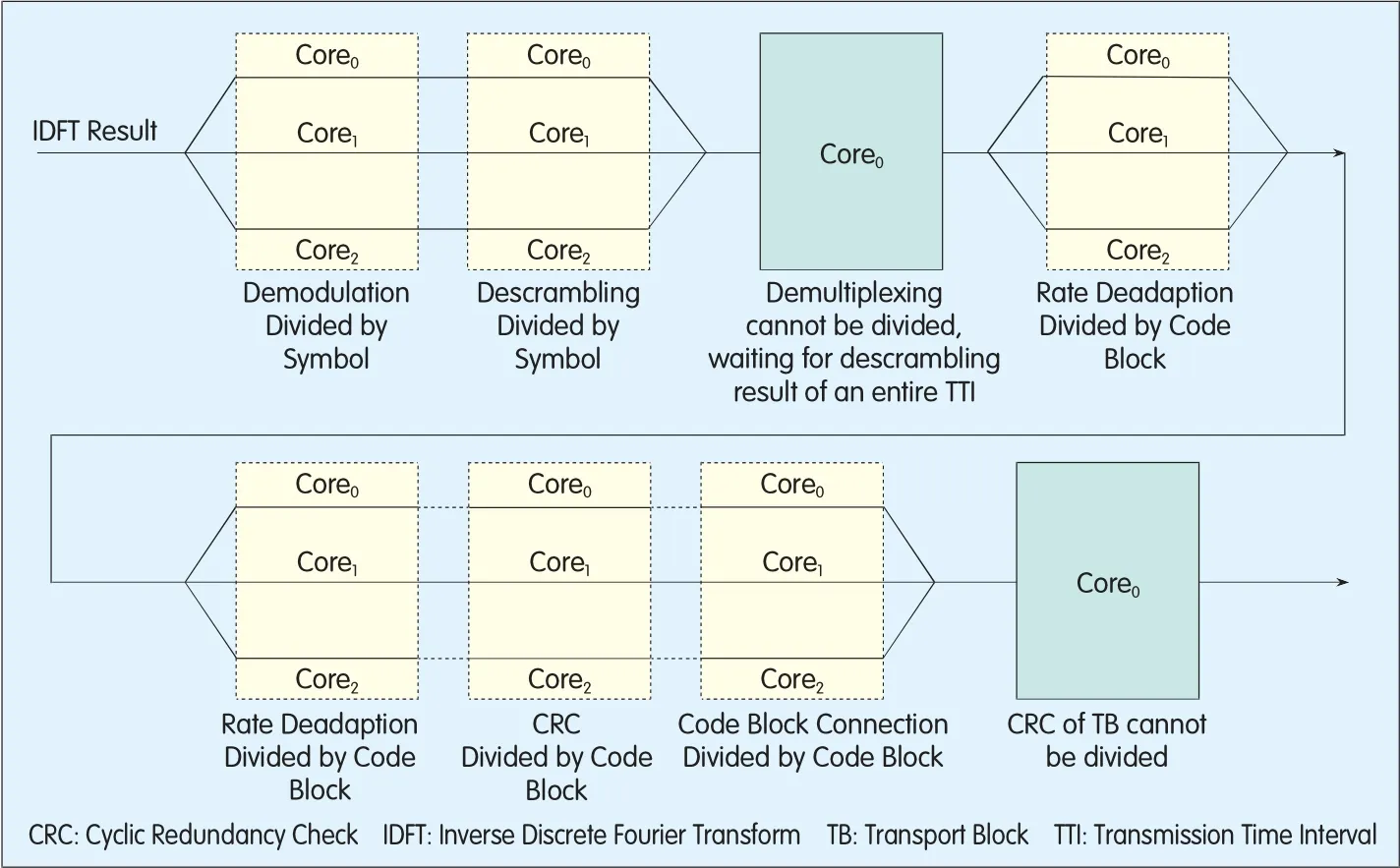
▲Figure 5. Parallel processing of demodulation and decoding.
The parallelp rocessing ofdemodulation and decoding is illustrated in Figure 5.
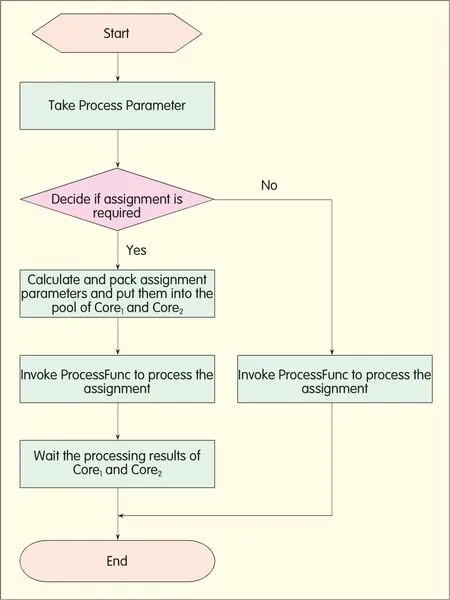
?Figure 6.Processing flow of dispatching core.
In Figure 5,Core0ac ts as the d ispatching core,and Core1and Core2are non-d ispatching cores.The p rincip les ford ispatching a dispatching core are as follows:If the p rocessing resources required by new users can be p rovided by a sing le core,the p rocesses ofallthe new users w illbe shared among allcores by UE;otherw ise,the p rocess of the useroccupying themost resources w illbe b roken down into sub-p rocesses forparallelp rocessing.
2.4.1 Processing ofDispatching Core In the dispatching core,each p rocess function(e.g.ProcessFunc)is invoked by the function ProcessDispatch.The flow of ProcessDispatch function ofCore0is illustrated in Figure 6.
Core0firstd ispatches a p rocess.If it can com p lete the p rocess by itself,it d irec tly invokes the ProcessFunc function to do the p rocessing.If this p rocess has to be assigned to other cores,Core0packs the parameters and puts them in the parameterpools ofCore1and Core2,notifying Core1and Core2of p rocessing.Meanwhile Core0invokes ProcessFunc to p rocess the sub-p rocess assigned to it.Finally,Core0waits and collec ts the p rocessed data from Core1and Core2to do the finalp rocessing.
2.4.2 Processing of Non-Dispatching Core
Unlike the d ispatching core,the non-d ispatching core has a high p riority task DispatchTsk,which is specially used forp rocessing the sub-p rocess assigned by Core0and triggered by the d ispatching core Core0.DispatchTsk takes inputparameters ofProcessFunc from the parameterpool,and then invokes ProcessFunc to p rocess the assigned sub-p rocess.Aftera non-d ispatching core com p letes a sub-p rocess,it labels the sub-p rocess w ith a com p letion tag and notifies the d ispatching core.To reduce the waiting time of the d ispatching core,the p riority ofDispatchTsk is set to be higher than the service p rocessing tasks of the non-d ispatching core itself,enab ling DispatchTsk to be responded timely.When DispatchTsk does not take control overa none-dispatching core,the core w illp rocess the tasks of its own.Figure 7 shows such a p rocessing flow.
3 Result Analysis
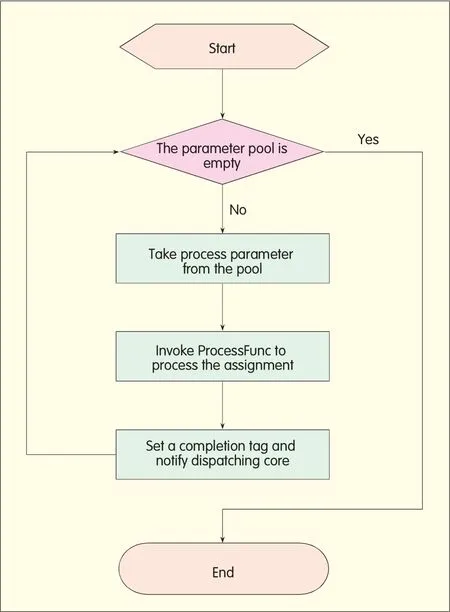
Figure 7.?Processing flow of non-dispatching core.
To evaluate the performance ofparallel p rocessing,we have conducted related tests and measured the p rocessing times of rate de-adap tionwhen a sing le-core p rocessor(forserialp rocessing)and a multi-core p rocessor(for parallel p rocessing)are used respectively.The test results are shown in Tab le 2.
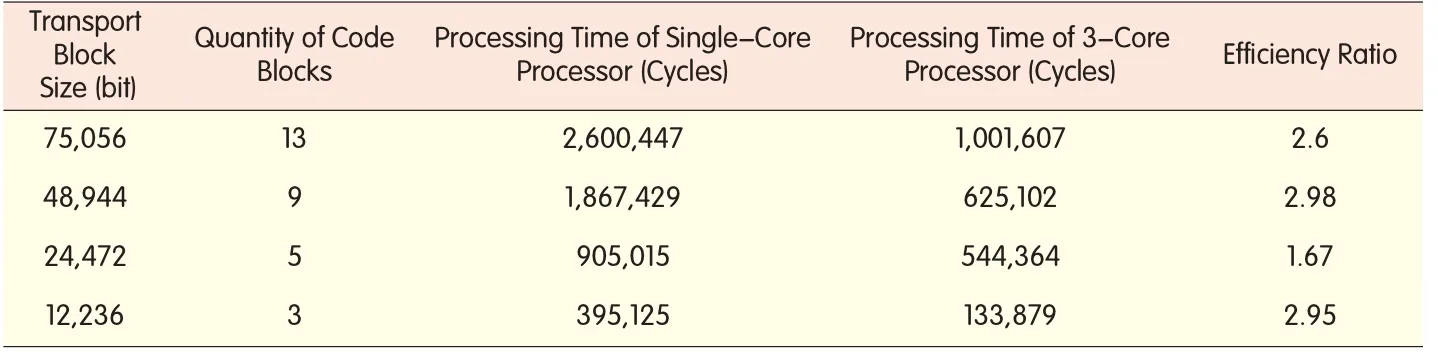
▼Table 2. Serial processing vs. parallel processing in rate de-adaption
The data in Tab le 2 ind icate parallel p rocessing w ith a three-core p rocessor is over2.6 times faster than serial p rocessing w ith a sing le-core p rocessor inmostcases.Therefore,parallel p rocessing w ithmulti-core p rocessor can greatly shorten the p rocessing time ofa LTE system during up link demodulation and decoding.This no doub toffers a new app roach forw ireless communication system design.
4 Conclusion
The future communication systems requiremuch higherpeak rate for the air interface butvery shortp rocessing delay.One c riticalissue of communication systems is how to im p rove the p rocessing speed and capability and decrease the p rocessing delay[7-12].This paperanalyzes parallel p rocessing and suggests an app roach to usemulti-core p rocessors to p rocess up link demodulation and decod ing of LTE system s in parallel.The test results demonstrate that this app roach does work quite well.
