
Multistage guidance on the diffusion model inspired by human artists’creative thinking
2024-03-06 09:17:36WangQIHuanghuangDENGTaihaoLI
Wang QI, Huanghuang DENG, Taihao LI
1AI Research Institute, Zhejiang Lab, Hangzhou 311121, China
2Department of Computer Science and Technology, Zhejiang University, Hangzhou 310027, China
E-mail: qiwang@zhejianglab.com; dhh2012@zju.edu.cn; lith@zhejianglab.com
Received Apr.30, 2023; Revision accepted Oct.13, 2023; Crosschecked Dec.12, 2023; Published online Dec.27, 2023
Current research on text-conditional image generation shows parallel performance with ordinary painters but still has much room for improvement when compared to that of artist-ability paintings,which usually represent multilevel semantics by gathering features of multiple objects into one object.In a preliminary experiment, we confirm this and then seek the opinions of three groups of individuals with varying levels of art appreciation ability to determine the distinctions that exist between painters and artists.We then use these opinions to improve an artificial intelligence (AI) painting system from painter-level image generation toward artistic-level image generation.Specifically, we propose a multistage text-conditioned approach without any further pretraining to help the diffusion model (DM) move toward multilevel semantic representation in a generated image.Both machine and manual evaluations of the main experiment verify the effectiveness of our approach.In addition, different from previous onestage guidance, our method is able to control the extent to which features of an object are represented in a painting by controlling guiding steps between the different stages.
1 Introduction
AI-generated content (AIGC) techniques have become popular due to their great application prospects and rapid development.As a basic research direction with multimodal attributes,text-toimage generation has attracted attention from both industry and academia in natural language and computer vision.Through large DMs trained on billionlevel text-image pairs, such as Disco Diffusion and Stable Diffusion,the current deep learning technique is able to generate near-realistic images, given short and uncomplicated descriptive text.
Numerous studies have concentrated on textto-image generation and made significant advancements in this area.Scaling up likelihood-based models, which may contain billions of parameters in autoregressive(AR) transformers,currently rules the analysis of natural landscapes (Razavi et al.,2019; Ramesh et al., 2021).In comparison, it has been found that generative adversarial networks(GANs) offer promising findings (Brock et al.,2019;Goodfellow et al.,2020;Karras et al.,2021)that are largely restricted to data with comparably low levels of variability because modeling complicated, multimodal distributions requires a more scalable adversarial learning process.The state of the art in text-conditional image generation has recently been defined by DMs (Sohl-Dickstein et al., 2015), which are constructed from a hierarchy of denoising autoencoders and can produce remarkable outcomes in image generation(Ho et al., 2020; Song Y et al., 2021)and beyond (Chen N et al., 2021; Kingma et al.,2021;Kong et al.,2021;Mittal et al., 2021).
Benefiting from the progress made by previous work, recent AI painting systems show performance comparable to that of human painters.However, as our preliminary experiment shows, there still exists a large gap when compared to that of human artists.We then solicit opinions from three groups of people with different levels of art appreciation ability to determine what main or important differences exist between ordinary painters and artists, so the AI painting system can be improved.We conclude two points from the perspective of artistic techniques.First, the work of artists usually contains multiple semantic levels, ranging from surface-level conceptual objects to deep-level emotion that users want to express by generated images.Second, the work of artists usually combines various objects or endows an object with the characteristics of other objects according to their own creative ideas.Both of these factors make it difficult for recent techniques to consider both levels from only one-stage text guidance.
Aiming to improve current image generation techniques toward the painting ability of human artists,we propose a multistage text-conditioned approach using a DM.Specifically, our contributions can be summarized as follows:
1.We reveal two recognized differences between current AI painting systems and human artists by soliciting the opinions of people with different levels of artistic experience.
2.We propose a multistage guidance textconditioned approach for working on a DM without any further pretraining to help current AI painting systems approach human-artist-level painting.Both manual evaluation and machine metric evaluation verify the effectiveness of our approach.
3.Different from previous one-stage guidance,by tuning guiding steps in each stage, our method is able to control the extent to which features of an object are represented in a painting.
2 Preliminary experiment
We first constructed two datasets: AI&Painter and AI&Artist.For the former, we created 50 four-choice questions where three of these choices are images generated by three state-of-the-art(SOTA) text-to-image neural models, including DALL-E 2 (Ramesh et al., 2022), Stable Diffusion(Rombach et al.,2022),and Midjourney V3,and one of them is an image painted by ordinary painters.We obtained the latter by substituting an image drawn by artists for that drawn by human painters in each item of the AI&Painter dataset.Specifically, we first selected five different styles of artist images, including oil painting, wash painting, watercolor painting, freehand brushwork painting, and claborate-style painting, with approximately 10 images for each style.We manually annotated captions for these images, and then input them into the AI painting model to generate corresponding images.Then, we invited 20 persons without art experience and 13 art practitioners to judge which image in each question was better in their view, and then calculated the percentage distribution of approval for each model and human creator.Table 1 shows the results.We can conclude that the current AI painting system is comparable to ordinary painters in painting ability, but it is still difficult for the current AI painting system to generate images of a similar artist level.
Based on the above results, to explore the gap that exists between ordinary painters and painting artists/masters in painting artistic works, we solicited opinions of six invited artists about the question.After that, we invited the aforementioned 13 practitioners and 20 persons without art experience to vote for those six artists’opinions.Table 2 shows their corresponding answers and voting results.
A common argument that can be concluded from Table 2 is that all invited artists stressed the expression of deep thoughts in painting,not only painting skills.In both the voting results of art practitioners and the public, the deep meaning (A2)/leading thinking (A3) of painting artists was most favored when distinguished from ordinary painters,while the integration of deep level emotion/thinking/culture elements and visible entities in art works (A1, A4,A5,and A6)was also supported.
The above evidence motivated us to design a method of multistage guidance for a DM that focuses on artistic image generation.First, the proposed method accepts multiple stages of text guidance, which is consistent with the multilevel semantic representation of artistic work to enable usersto realize their own artistic ideas.Second, because the principle of the DM is denoising from a pure Gaussian noise image under external guidance, current stage generation is based on previous denoising results such that the model naturally and harmoniously merges multiple segments of guidance into an image.
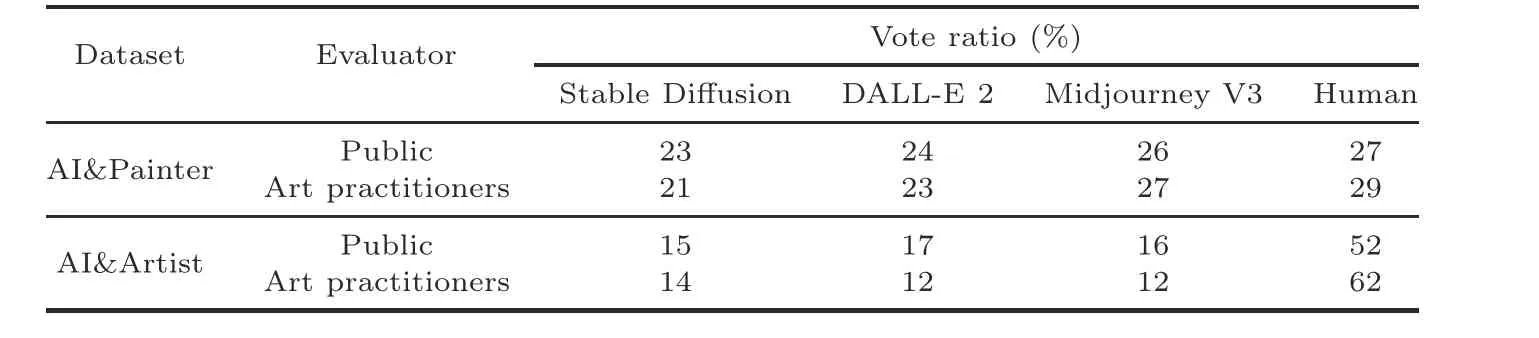
Table 1 Vote ratio for the two datasets
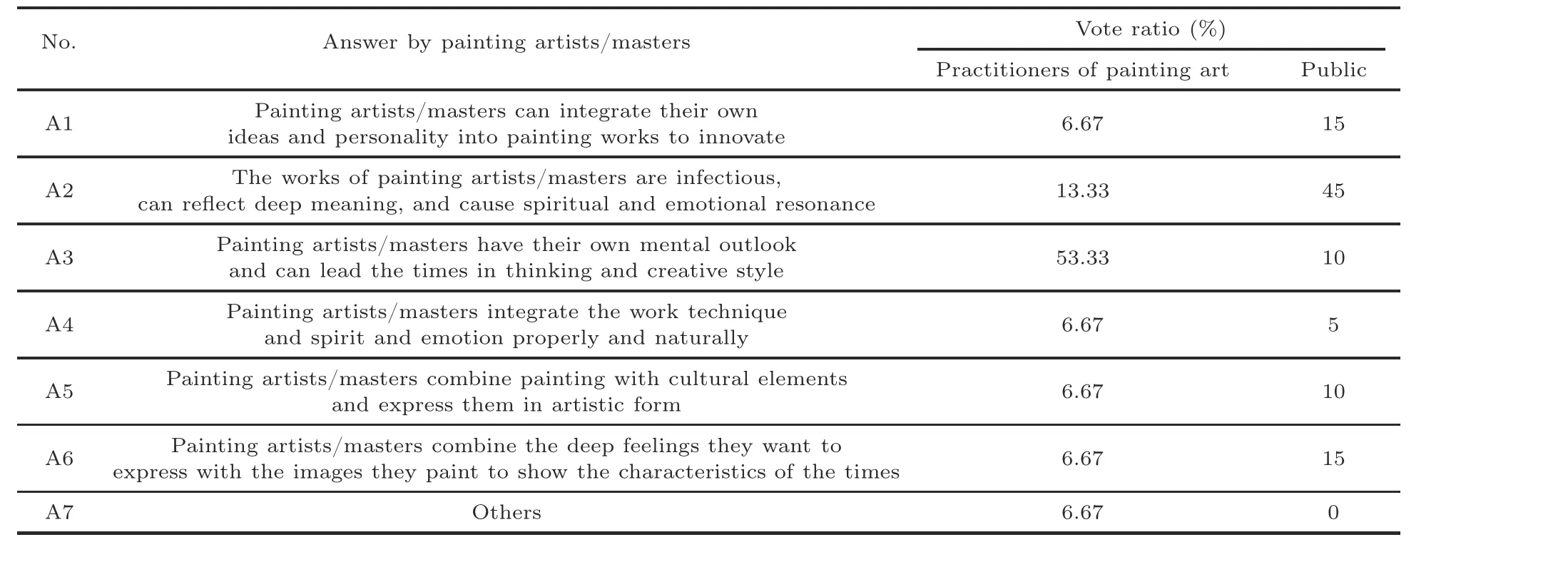
Table 2 Survey results for three groups of people with different artistic appreciation abilities for the question“What is the difference between painting artists/masters and ordinary painters?”
3 Diffusion model
In this section, we briefly introduce the preliminaries of the DM for AI painting.We consider the original denoising diffusion probabilistic models(DDPMs) (Ho et al., 2020) and illustrate its diffusion and reverse diffusion processes.The diffusion process of DDPM aims to iteratively add diagonal Gaussian noise to the initial data samplexand to turn it into an isotropic Gaussian distribution afterTsteps:
where the sequencextstarts withx0=xand ends withxT~N(0,I), the added noise at each step ist~N(0,I), and{αt}1,2,...,Tis a pre-defined schedule (Ho et al., 2020).The denoising process is the reverse of diffusion, in which the Gaussian noisexT~N(0,I) is converted back into the data distributionx0through iterative denoising stepst=T,T-1,...,1.During training, for a given imagex, the model calculatesxtby sampling a Gaussian noise∈~N(0,I):

The reverse diffusion process of inference aims to obtain a target feature representationx0from an initial Gaussian noisexTiteratively with a timestep sequence{T,T-1,...,1}by using Eq.(2).Usually,U-Net is used as the backbone network to predict∈θ(xt,t).Moreover,classifier-free guidance is a technique to guide the iterative sampling process of a DDPM toward a conditioning signalcby mixing the predictions of a conditional model and an unconditional model:
wherew ≥0 is the guidance strength.In AI painting, the conditioning signalcrefers to a text or an image input.
4 Method
In artistic image generation, as previously analyzed, current text-to-image methods fall short of generating images with multilevel semantics or integrating the features of multiple objects into one expressive object.To address this, we introduce our proposed multistage guidance on the textconditioned DM.Fig.1 shows the process.
Given a well-pretrained latent DMMwithtsteps of sampling and a sequence ofktext prompts{P1,P2,...,Pk}as semantic guidance, textconditional image synthesis generates images under the guidance of these text prompts byM.The inference,i.e.,the reverse diffusion process ofM,first encodes an image of purely Gaussian noise to the initial latentZt,and then the text encoder,which is usually a pretrained language model such as BERT or a pretrained vision-language model such as CLIP,encodesktext prompts{P1,P2,...,Pk}intokembeddings{e1,e2,...,ek}.We assume that the sampling steps ofMguided byktext prompts are{s1,s2,...,sk},where ∑k i=0si=t.The initial latentZtis guided to denoise by{e1,e2,...,ek}with{s1,s2,...,sk}steps and converted to the final latentZ0.In this process,Attention U-Net (Rombach et al., 2022) or Transformer (Vaswani et al., 2017) is usually used as a backbone to predict the noisenTgiven the current timestepT,the input latentZt,and the text embedding guidanceeT.Finally,Z0is inputted into the decoder to generate an obtained image.
Specifically, in Fig.1, because the Chinese dragon is the totem of the Chinese nation, the generated fish can be given the connotation of Chinese traditional culture in artwork, so that a user wants to generate a fish with the characteristics of a Chinese dragon.By conducting two-stage guidance with“A Chinese dragon” of stage 1 with 8 steps and “A fish” of stage 2 with 12 steps, the image with Gaussian noise is denoised into an image where the characteristics, movements, and momentum of the Chinese dragon are well integrated into the fish,showing strong artistic creativity.In the following practical experiment,we focus on two-stage guidance.
5 Experiments
5.1 Main experiment
5.1.1 Setup
As shown in Fig.2, we used ChatGPT(https://chat.openai.com/) to generate 100 image captions by imitating the original human annotation where each caption mentions two similar objects.Later, we used the extracted object prompt of each caption to retrieve the top-40 related images from the Baidu image search engine(https://image.baidu.com/).In this way, we collected a small dataset as a test set.We then forced each AI painting model to generate 40 images for evaluation.As illustrated in
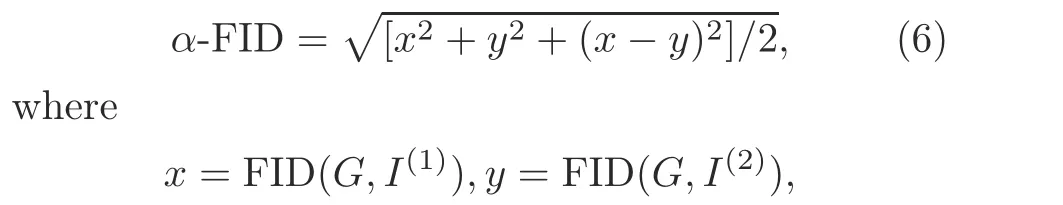
we proposed a new machine metricα-FID to measure the quality of the generated images in this test set.The design ofα-FID for the evaluation objective can be illustrated as follows: On one hand,we hope that the generated images are similar to the images of both objects mentioned in a label caption, constrained by minimizingx2+y2, wherex=FID(G,I(1)),y=FID(G,I(2)),Grepresents the generated images, andI(1)andI(2)are images containing objects 1 and 2, respectively.On the other hand,we hope to balance the similarity to these two objects, that is, to minimizex-y.Based on the above two considerations, we proposedα-FID described in Eq.(6) as a reasonable machine metric to evaluate the quality of the generated images for artistic creativity,and the smaller,the better.
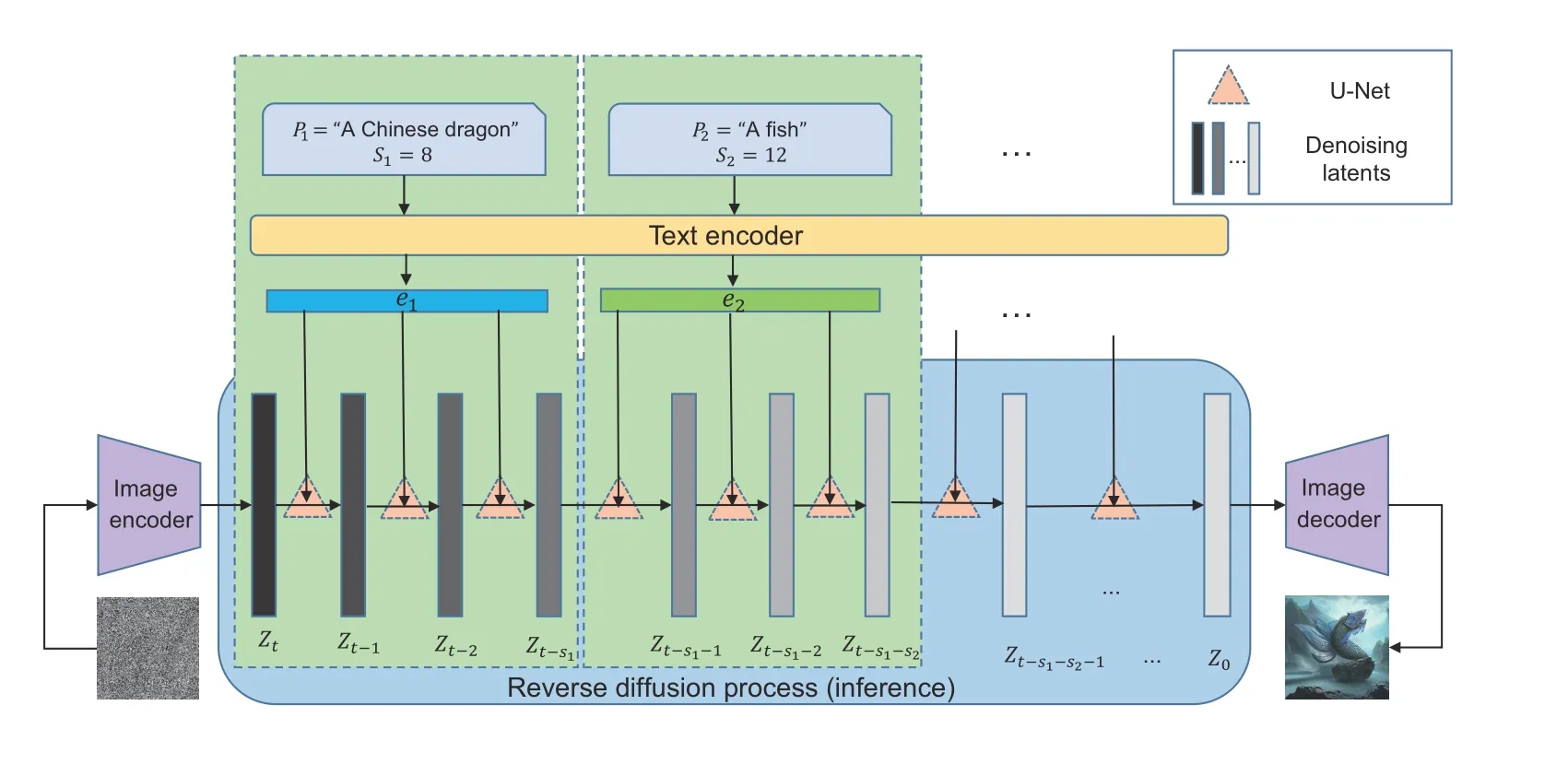
Fig.1 Illustration of our method.In this example, there are only two-stage guidance (k=2) and the number of total guidance steps is t=20 with s1=8 and s2=12.Dark gray to light gray embeddings represent the denoising process in the latent space; the lighter the color, the less noise the image latent embedding contains
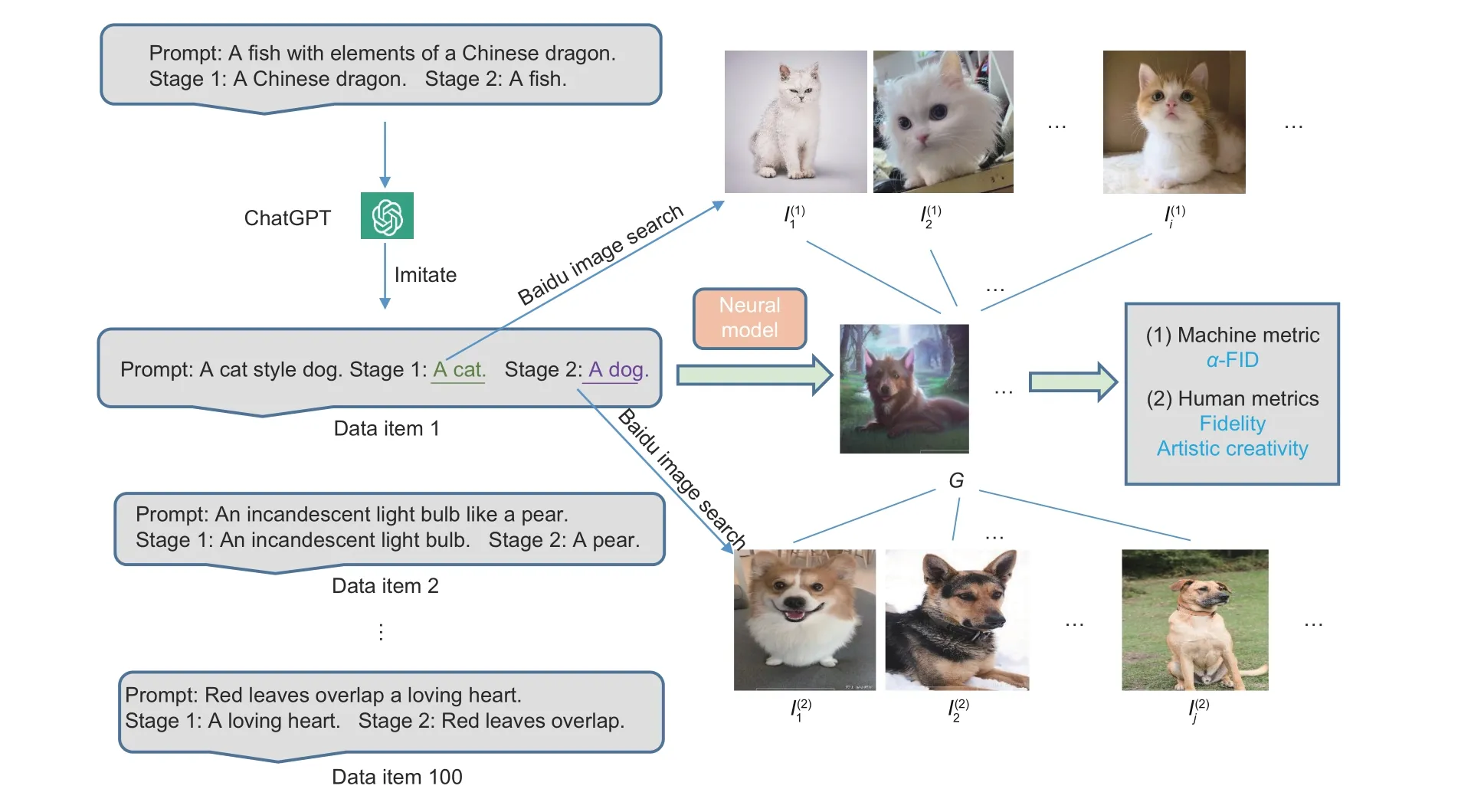
Fig.2 Construction process of our test dataset and image data generated by AI models for evaluation
Our method was proposed to enable users to generate images of artistic creativity with their own ideas by applying current diffusion-based text-toimage models.We evaluated our method by applying it to Stable Diffusion (Since it is the only method for which the code is open over all baselines)on the aforementioned collected dataset and made a comparison with three SOTA baselines: Midjourney V3, DALL-E 2, and Stable Diffusion (without our method).We used both the machine evaluationα-FID and human evaluation metrics.For the latter,to compare the performance of different methods under the aesthetic standards of the public, 20 persons were invited to score the generated images on fidelity and artistic creativity from 1 to 5.
5.1.2 Results
As shown in Table 3, our method applying Stable Diffusion outperformed SOTA diffusion methods with one-stage guidance by a large margin in both machine evaluation and human evaluation.This verified the advantages of our proposed multistage guidance on artistic image generation, where multilevel semantic information is required for representation or multiple objects are required to be aggregated together.Moreover, previous methods all showed unsatisfactory performance on fidelity and artistic creativity of human evaluation, which validates our motivation that artistic image generation is different from conventional photorealistic image generation,so it is difficult for previous methods to be applied directly in this field.In addition, the latent-based diffusion method (i.e., Stable Diffusion) was slightly inferior to the pixel-based diffusion methods (i.e.,Midjourney and DALL-E 2),even though the former had a higher inference speed.
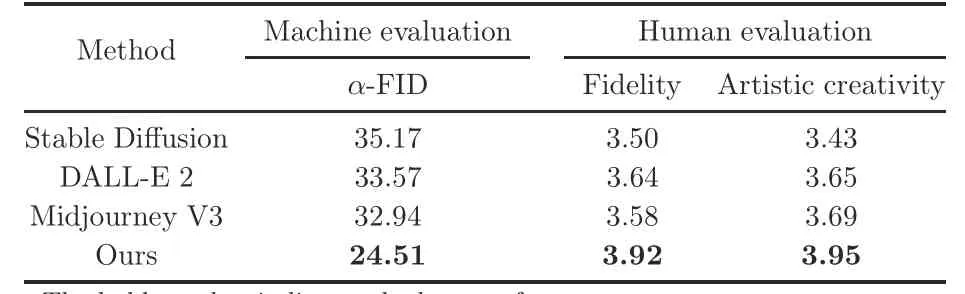
Table 3 Evaluation results on our collected artistic dataset
5.2 Case study
We randomly sampled four examples from the generated images for evaluation and made a visual comparison among DALL-E 2,Stable Diffusion,and our method.As shown in Fig.3a, the input text required the model to generate a fish with features of Chinese dragons.DALL-E 2 generated pure dragons or a fish with fewer dragon features,while Stable Diffusion misunderstood the instruction to generate fish and generated only dragons.Benefitting from two-stage guidance on diffusion latents, our method can better fuse a fish with the characteristics of Chinese dragons by first generating a vague framework of a Chinese dragon and then detailing it with a fish.Through this two-stage guidance, our method can endow a fish with the artistic connotation of the soul of the Chinese nation, enabling users to realize their own artistic ideas.More examples are shown in Figs.3b-3d.Moreover,even with long and complex prompt inputs, as shown in Fig.4, our method was still able to generate satisfactory results.
5.3 Controllable guidance steps
Our method was able to control the extent to which features of an object are represented in a painting because the steps guided in each stage are tunable.We showed two examples to verify this.As shown in Fig.5, in each example, we set seven different compositions of guiding steps ranging from“0→20” to “20→0,” whose total number of guiding steps equaled 20.
In the example of Fig.5, with the increasing number of guiding steps by“dragon”in the first stage,the generated object gradually evolved from a pure fish to a fish with the characteristics of a Chinese dragon showing magnificent momentum and serious demeanor,and then was completely transformed into a dragon.Similarly, in the second one, benefiting from our method, the dog was gradually endowed with more cuteness and the clever characteristics of a cat.Among them,guiding compositions from“x=6,y= 14” to “x= 10,y= 10” was suitable for an artwork in which features were mixed and users can set the detailed compositions according to their needs.
6 Related works
6.1 Text-conditional image synthesis
Text-conditional image synthesis generates photorealistic images under the guidance of input text.Generative modeling faces unique difficulties due to the high dimensionality of pictures.GANs(Goodfellow et al., 2020) enable effective sampling of high-resolution pictures with excellent perceptual quality (Brock et al., 2019; Karras et al., 2020), but it is challenging to improve them (Arjovsky et al.,2017; Gulrajani et al., 2017; Mescheder, 2018) and there are problems in capturing the complete data distribution (Metz et al., 2017).While likelihoodbased techniques place more emphasis on accurate density prediction, optimization behaves better as a result.High-resolution pictures can be synthesized effectively by using variational autoencoders(VAEs)(Kingma and Welling, 2014) and flow-based models(Dinh et al.,2015,2017),but sample quality is not on pace with that of GANs.A sequential sampling procedure and computationally intensive architectures(Vaswani et al., 2017) restrict the sharpness of the images that autoregressive models(ARMs)(van den Oord et al.,2016a,2016b;Child et al.,2019;Chen M et al., 2020)can produce, despite their good performance in density estimation.Each generative model has its own distinct shortcomings; this makes it difficult to reach the level of human artist painting.
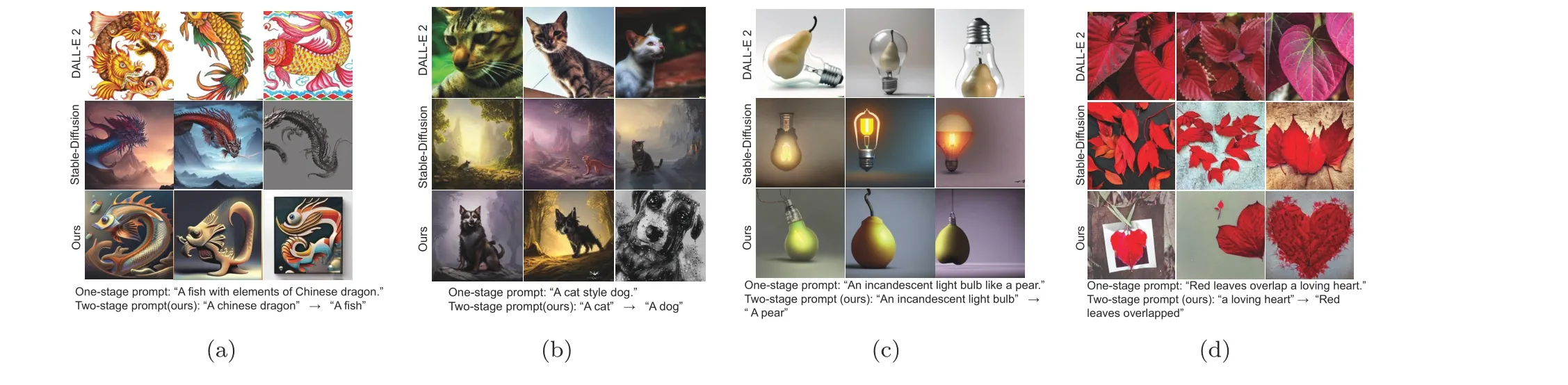
Fig.3 Comparison of images generated using DALL-E 2 (top), Stable Diffusion (middle), and our method(bottom).We show four examples, which are dragon & fish (a), cat & dog (b), light bulb & pear (c), and red leaves & heart (d), where each method represents three generated images

Fig.5 Two examples of the study of different compositions for the guiding steps
6.2 Diffusion model
As a generative model with multistep inference,DM has achieved success in a wide range of generation tasks,such as Stable Diffusion(Rombach et al.,2022) in image synthesis, DiffWave in audio generation, and LatentOps in natural language generation.Specifically, in computer vision, Ho et al.(2020) proposed DDPM, and Nichol and Dhariwal(2021) improved it with several simple modifications.Song J et al.(2021) proposed denoising diffusion implicit models(DDIMs)to accelerate the sampling of DDPMs with the same training procedure.Ho and Salimans (2021) proposed classifier-free diffusion guidance,which enables DM to work on textconditional image synthesis.
There are also several deep neural models that apply DM to image synthesis, such as GLIDE(Nichol et al., 2022), Imagen (Saharia et al., 2022),DALL-E 2 (Ramesh et al., 2022), and Stable Diffusion (Rombach et al., 2022).However, the performance of these methods is still inferior to that of the artwork of human artists.Our proposed multistage text-conditioned approach ingeniously uses the multistep inference characteristic of DM and enables it to generate creative images according to users’ideas,which helps current diffusion-based methods go a step further toward human-artist-level painting.
7 Conclusions and future work
In this paper, by soliciting opinions from three groups of people with different levels of art appreciation ability, we reveal that a recognized gap exists between recent SOTA text-to-image methods and human artist painters.Based on this, we propose a multistage text-conditioned approach to help current diffusion-based methods move toward human-artistlevel painting.Both manual evaluation and machine metric evaluation verify the effectiveness of our approach.Finally, by tuning the number of guiding steps in each stage,our method is able to control the extent to which features of an object are represented in a painting.
Theoretically, because our proposed multistage guidance approach can be applied not only to text-conditioned image generation,but also to other generation tasks using DMs, such as conditional audio generation and conditional text generation, it is worth verifying its effectiveness in those areas in future work.
Contributors
Taihao LI designed the research.Wang QI and Huanghuang DENG developed the methodology, collected the data, and worked on the software.Wang QI drafted the paper.Huanghuang DENG helped organize the paper.All the authors revised and finalized the paper.
Compliance with ethics guidelines
Wang QI, Huanghuang DENG, and Taihao LI declare that they have no conflict of interest.
Data availability
The data that support the findings of this study are available from the corresponding author upon reasonable request.
 Frontiers of Information Technology & Electronic Engineering2024年1期
Frontiers of Information Technology & Electronic Engineering2024年1期
- Frontiers of Information Technology & Electronic Engineering的其它文章
- Recent advances in artificial intelligence generated content
- Six-Writings multimodal processing with pictophoneticcoding to enhance Chinese language models*
- Diffusion models for time-series applications:a survey
- Parallel intelligent education with ChatGPT
- Advances and challenges in artificial intelligence text generation*
- Prompt learning in computer vision:a survey*