
基于LSM Tree的分布“索引實(shí)現(xiàn)
2016-11-29 09:34:20隆飛翁海星高明張召
隆飛,翁海星,高明,張召
(華東師范大學(xué)數(shù)據(jù)科學(xué)與工程研究院,上海200062)
基于LSM Tree的分布“索引實(shí)現(xiàn)
隆飛,翁海星,高明,張召
(華東師范大學(xué)數(shù)據(jù)科學(xué)與工程研究院,上海200062)
近年來Log-Structured-Merge(LSM)Tree在NoSQL系統(tǒng)中得到了廣泛地應(yīng)用.主要是因?yàn)長(zhǎng)SM Tree架構(gòu)提出了延遲更新和批量寫入的算法,將隨機(jī)寫轉(zhuǎn)換為批量寫,減少了磁盤臂的移動(dòng)開銷,從而大大地提升了數(shù)據(jù)庫(kù)的寫入性能.然而,讀性能卻也因此受到影響.LSM Tree和B Tree之間的本質(zhì)區(qū)別使得NoSQL系統(tǒng)不適宜直接引用B Tree作為輔助索引結(jié)構(gòu).本文實(shí)現(xiàn)了LSM Tree下的一種分布式輔助索引結(jié)構(gòu),提出針對(duì)這種讀寫分離架構(gòu)的索引批量加載策略,并對(duì)LSM Tree的查詢計(jì)劃樹進(jìn)行了緩沖優(yōu)化,避免了重復(fù)的查詢解析,使得索引讀的性能得到了相應(yīng)的提升.
輔助索引;日志結(jié)構(gòu)合并樹;NoSQL
0 引言
近些年,伴隨著數(shù)據(jù)采集設(shè)備的快速發(fā)展,用戶成為產(chǎn)生數(shù)據(jù)的主體,產(chǎn)生的數(shù)據(jù)總量往往會(huì)達(dá)到TB甚至PB級(jí)別.集中式數(shù)據(jù)庫(kù)在處理這些數(shù)據(jù)時(shí),代價(jià)高昂.因此,水平擴(kuò)展良好的NoSQL數(shù)據(jù)庫(kù)應(yīng)運(yùn)而生,并迅速發(fā)展起來.大多數(shù)NoSQL系統(tǒng)都是基于key-value形式的存儲(chǔ)架構(gòu),例如HBase[1],LevelDB,Apache Cassandra[2]等.它們都是搭建于廉價(jià)的硬件設(shè)施之上,往往適用于對(duì)數(shù)據(jù)庫(kù)的伸縮性,高性能,高可用和低成本有更高要求的應(yīng)用.
無(wú)論是傳統(tǒng)的關(guān)系型數(shù)據(jù)庫(kù)抑或是新型NoSQL數(shù)據(jù)庫(kù),更高的數(shù)據(jù)查詢速度始終是不變的追求.典型的NoSQL系統(tǒng)只支持key上的查詢操作,對(duì)于value上的查詢操作支持都不是很友好,但許多應(yīng)用需要快速查詢value列的某一行,因此它們對(duì)于NoSQL上的輔助索引的需求也越來越迫切.為了滿足NoSQL數(shù)據(jù)庫(kù)對(duì)于輔助索引的需求,本文實(shí)現(xiàn)了解決大規(guī)模數(shù)據(jù)量的分布式輔助索引功能,設(shè)計(jì)了針對(duì)Log-Structured-Merge(LSM)[3]體系的批量加載策略以解決基線數(shù)據(jù)上索引的構(gòu)建任務(wù),通過使用索引列進(jìn)行查詢,能夠大大提高對(duì)數(shù)據(jù)表中非主鍵數(shù)據(jù)的查詢性能.
分布式存儲(chǔ)引擎下的索引實(shí)現(xiàn)對(duì)于NoSQL類系統(tǒng)有著重大的意義,同時(shí)它的研究已經(jīng)成為查詢效率研究的熱點(diǎn)之一.例如,華為公司實(shí)現(xiàn)在HBase上建立輔助索引HIndex[4], Google Spanner[5]中支持高并發(fā)跨數(shù)據(jù)中心情況下滿足事務(wù)一致性的索引,Chen et al[6]提出了一種云端類DBMS的索引框架,華東師范大學(xué)數(shù)據(jù)工程研究院在阿里的數(shù)據(jù)庫(kù)Oceanbase上實(shí)現(xiàn)輔助索引[7]等等.
本文的章節(jié)安排如下:第1節(jié)首先介紹了背景及其研究現(xiàn)狀,包括LSM Tree模型和其存儲(chǔ)架構(gòu);第2節(jié)描述了輔助索引的結(jié)構(gòu),闡述了輔助索引的單點(diǎn)存儲(chǔ)方式和分布式存儲(chǔ)方式;第3節(jié)是介紹了分布式存儲(chǔ)架構(gòu)下輔助索引的實(shí)現(xiàn)細(xì)節(jié);在第4節(jié),本文做了一些實(shí)驗(yàn)來驗(yàn)證輔助索引為查詢帶來的性能提升,并針對(duì)本文對(duì)輔助索引所做的一些優(yōu)化進(jìn)行了實(shí)驗(yàn)驗(yàn)證;第5節(jié)作為全文的總結(jié)并分析了未來工作.
1 基于LSM-Tree的分布式存儲(chǔ)系統(tǒng)架構(gòu)
LSM模型誕生于1996年.自Google公司的BigTable[8]論文發(fā)表之后,LSM模型受到大量的關(guān)注.LSM對(duì)于數(shù)據(jù)的變化采用的是延遲和批量寫的算法,將內(nèi)存與磁盤中的數(shù)據(jù)級(jí)聯(lián)在一起.與傳統(tǒng)的B Tree相比,LSM會(huì)先將一段時(shí)間內(nèi)的插入操作緩沖在內(nèi)存,當(dāng)內(nèi)存達(dá)到閾值時(shí),再將內(nèi)存中的數(shù)據(jù)和磁盤上的數(shù)據(jù)做合并,并順序?qū)懭胍粋€(gè)或多個(gè)磁盤頁(yè).這種順序?qū)懴啾扔陔S機(jī)寫,能夠明顯地減少磁盤臂的移動(dòng),會(huì)快很多;因此LSM Tree能夠提升數(shù)據(jù)庫(kù)的寫入性能.比較適合LSM-Tree的應(yīng)用場(chǎng)景是:insert數(shù)據(jù)量大,讀數(shù)據(jù)量和update數(shù)據(jù)量不高且讀一般針對(duì)最新數(shù)據(jù),例如歷史庫(kù)和日志文件.Diff-index[9]論文指出LSM是針對(duì)寫作了優(yōu)化的而B Tree對(duì)讀和寫都只做了一些簡(jiǎn)單的優(yōu)化.
LSM Tree由許多位于磁盤上的樹結(jié)構(gòu)成分和一個(gè)駐留在內(nèi)存當(dāng)中的成分組成.數(shù)據(jù)按照主鍵排序,以SSTable[8](Sorted String Table)的形式存儲(chǔ)在磁盤組件中.如圖1所描述,分布式LSM架構(gòu)將數(shù)據(jù)分為增量數(shù)據(jù)和基線數(shù)據(jù),分別存儲(chǔ)在更新服務(wù)器和基線服務(wù)器上.圖中包含一個(gè)內(nèi)存組件和三個(gè)磁盤組件.當(dāng)客戶端發(fā)起更新請(qǐng)求時(shí),首先會(huì)在磁盤上追加一行操作日志,然后,將更新的數(shù)據(jù)寫入到C0 Tree當(dāng)中.當(dāng)內(nèi)存達(dá)到存儲(chǔ)閾值,LSM Tree會(huì)發(fā)起合并流程.為了取回?cái)?shù)據(jù)的實(shí)際值,讀操作不得不對(duì)每個(gè)磁盤中的樹結(jié)構(gòu)上進(jìn)行查詢.

圖1 LSM存儲(chǔ)模型Fig.1LSM storing model
在一些大規(guī)模數(shù)據(jù)分析的應(yīng)用當(dāng)中,相對(duì)于整個(gè)數(shù)據(jù)庫(kù),更新數(shù)據(jù)量往往不是很多.對(duì)于這部分?jǐn)?shù)據(jù),可以直接存放在內(nèi)存當(dāng)中.如圖2所示,在讀寫分離情況下,內(nèi)存數(shù)據(jù)往往存放在一個(gè)單獨(dú)的服務(wù)器當(dāng)中,稱為UpdateServer(UPS),對(duì)應(yīng)LSM中的C0組件.基線數(shù)據(jù)存儲(chǔ)在Chunkserver(CS)中.根據(jù)應(yīng)用的規(guī)模,可以對(duì)CS水平擴(kuò)展.在CS上實(shí)現(xiàn)LSM的不同級(jí)別的存儲(chǔ).Rootserver(RS)是整個(gè)集群的管理者,管理集群中的所有服務(wù)器,數(shù)據(jù)分布,元數(shù)據(jù)信息以及副本信息.為保證RS的高可用性,通常RS采取主備架構(gòu),主備之間強(qiáng)一致. MergeServer(MS),是SQL解析模塊,產(chǎn)生查詢計(jì)劃,并將每個(gè)Tablet的讀取請(qǐng)求發(fā)送到相應(yīng)的CS.CS首先讀取磁盤中包含的基準(zhǔn)數(shù)據(jù),接著請(qǐng)求UPS,獲取相應(yīng)的增量數(shù)據(jù),并將基準(zhǔn)數(shù)據(jù)與增量數(shù)據(jù)融合后得到最終結(jié)果,返回給Client[10].
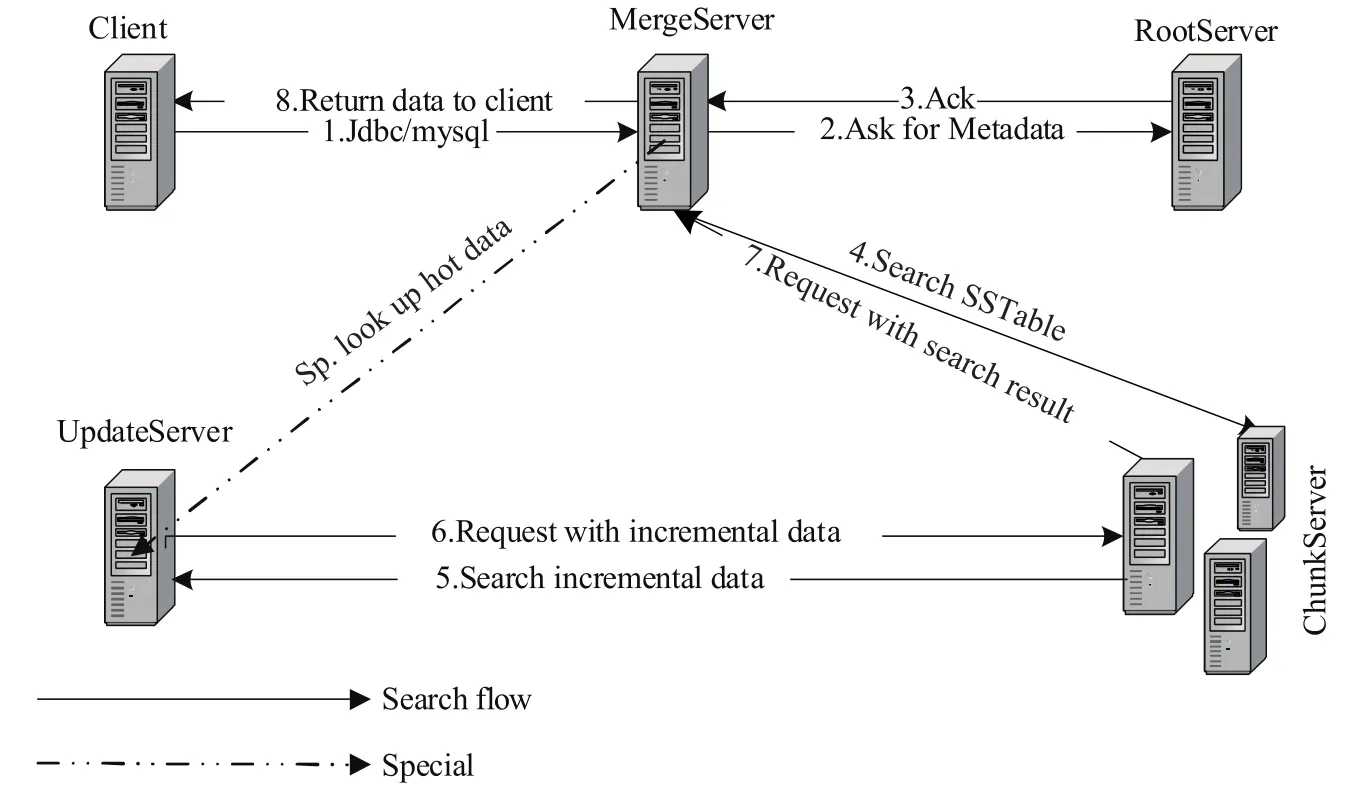
圖2 分布式存儲(chǔ)架構(gòu)圖Fig.2Distributed system architecture
2 輔助索引結(jié)構(gòu)描述
2.1 索引存儲(chǔ)結(jié)構(gòu)
對(duì)于許多NoSQL系統(tǒng)而言,數(shù)據(jù)是以key-value對(duì)的形式組織在磁盤當(dāng)中的.Key-value對(duì)是最簡(jiǎn)單的非基本數(shù)據(jù)模型之一,一些其他更復(fù)雜的數(shù)據(jù)模型則都是在它的基礎(chǔ)之上建立的.由此本文定義了數(shù)據(jù)的存儲(chǔ)模式:D={t|t=〈key,{values}〉}.此模式將數(shù)據(jù)庫(kù)定義為元組的集合,元組以〈key,{values}〉的形式存儲(chǔ)在磁盤上,并按照key值對(duì)數(shù)據(jù)進(jìn)行排序, values是多個(gè)value的集合.key類似于傳統(tǒng)數(shù)據(jù)庫(kù)中的主鍵,不允許重復(fù),因此key所在列構(gòu)成NoSQL系統(tǒng)中的主索引.
隨著越來越多的應(yīng)用采取NoSQL系統(tǒng)作為數(shù)據(jù)管理系統(tǒng),而這些應(yīng)用的負(fù)載大多是以value列為查詢列,因此主索引無(wú)法滿足應(yīng)用的需求,建立value列上的輔助索引的需求也越來越強(qiáng)烈.傳統(tǒng)的輔助索引定義形式如下:M={t|t=〈search key,pointer〉}.傳統(tǒng)的輔助索引包括BTree索引和Hash索引等,都是將索引組織在內(nèi)存當(dāng)中,并以pointer的方式定位到磁盤中的數(shù)據(jù).這種方式對(duì)處理海量數(shù)據(jù)的分布式數(shù)據(jù)庫(kù)并不適用[11],主要原因有:維護(hù)代價(jià)大;制約了數(shù)據(jù)庫(kù)的水平擴(kuò)展性等.
本文提出一種基于讀寫分離式LSM架構(gòu)的索引結(jié)構(gòu),其存儲(chǔ)模式如下所示:MD={D mem+D disk|D mem={〈search key+primary key,{covering}〉},D disk= {〈search key+primary key,{covering}〉}}.索引分為兩個(gè)部分:位于UPS中D mem部分和位于磁盤中的D disk部分.其存儲(chǔ)結(jié)構(gòu)中摒棄了傳統(tǒng)索引的指針部分,而將search key和primary key作為索引存儲(chǔ)結(jié)構(gòu)的聯(lián)合主鍵.與傳統(tǒng)數(shù)據(jù)庫(kù)類似,使用冗余列來實(shí)現(xiàn)覆蓋索引(covering index),避免二次查詢操作,從而提高查詢效率.
在實(shí)現(xiàn)中,索引表按照聯(lián)合主鍵水平切分成多個(gè)tablet.每個(gè)tablet按照一定的策略均勻分布到集群中的CS上,滿足基線和增量數(shù)據(jù)分離特性,并由RS執(zhí)行負(fù)載均衡.實(shí)驗(yàn)證明這種適應(yīng)于架構(gòu)的索引實(shí)現(xiàn)方法可以很好地滿足非主鍵列查詢需求.

圖3 索引表存儲(chǔ)模型Fig.3Storage model of secondary index
必須強(qiáng)調(diào)的是,本文的實(shí)現(xiàn)方法與傳統(tǒng)的索引實(shí)現(xiàn)差別較大,但是能夠滿足索引高可擴(kuò)展性以及高可用性的需求.從本質(zhì)上說,索引表就是存儲(chǔ)在數(shù)據(jù)庫(kù)中的另一張數(shù)據(jù)表.圖3中給出存儲(chǔ)的一個(gè)示例,輔助索引表Si1(Secondary index 1)將索引列和原數(shù)據(jù)表T1(Table1)的主鍵列作為自身的聯(lián)合主鍵,同時(shí)添加一些附加列信息.T1物理上按照主鍵列進(jìn)行排序,并水平切分成為T1c1,T1c2和T1c3三個(gè)部分,分別存儲(chǔ)在CS1,CS2和CS3上.Si1按聯(lián)合主鍵在磁盤上重新排序,Si1c1,Si1c2和Si1c3是其對(duì)應(yīng)的水平切片.T1的第一主鍵是itemkey,而Si1的第一主鍵是type.
輔助索引表構(gòu)建時(shí),并不構(gòu)造出整張表.而是直接在每個(gè)CS上直接構(gòu)造輔助索引的每個(gè)部分.并將構(gòu)造完成的每個(gè)SSTable的主鍵范圍信息匯報(bào)給RS,然后由RS發(fā)起拷貝副本的操作.
2.2 索引特征分析
存儲(chǔ)代價(jià):分布式數(shù)據(jù)庫(kù)中引入索引對(duì)原來的系統(tǒng)的影響主要體現(xiàn)在更新數(shù)據(jù)表時(shí)帶來的額外代價(jià)和索引存儲(chǔ)的額外代價(jià).然而,索引表一般只存儲(chǔ)數(shù)據(jù)表的某些列,其存儲(chǔ)空間遠(yuǎn)遠(yuǎn)小于數(shù)據(jù)表,屬于可接受范圍.因?yàn)楦虏僮骶赨PS的內(nèi)存中完成,時(shí)間成本也遠(yuǎn)遠(yuǎn)小于磁盤讀操作,因此其對(duì)于性能的影響也可以接受.
可擴(kuò)展性和彈性:本文實(shí)現(xiàn)的索引功能支持水平擴(kuò)展,不會(huì)影響數(shù)據(jù)庫(kù)的可擴(kuò)展性.通過增加集群當(dāng)中的CS和MS的數(shù)量,集群的整體性能“線性可擴(kuò)展”.并且索引支持在集群運(yùn)行過程當(dāng)中,動(dòng)態(tài)增加結(jié)點(diǎn),彈性良好.
可用性:創(chuàng)建索引表的時(shí)候可以指定索引表在集群中的副本數(shù)目.在索引批量加載的過程中會(huì)在不同的CS上創(chuàng)建多份副本,以保證索引數(shù)據(jù)的可用性.目前,在構(gòu)建索引過程中,CS發(fā)生故障會(huì)影響到索引的構(gòu)建過程,每日合并結(jié)束后,索引狀態(tài)不可用.索引創(chuàng)建失敗不會(huì)影響集群的正常使用.
3 索引實(shí)現(xiàn)及維護(hù)
索引實(shí)現(xiàn)分為兩個(gè)部分,一部分是索引構(gòu)建完成后動(dòng)態(tài)維護(hù)部分,這部分內(nèi)容比較簡(jiǎn)單,實(shí)現(xiàn)時(shí)只需保證原數(shù)據(jù)表和索引表之間的數(shù)據(jù)一致性即可;另一部分是對(duì)原表上已經(jīng)存在的數(shù)據(jù)的處理,必須將此部分?jǐn)?shù)據(jù)同步到索引表中.很自然的想法是將原數(shù)據(jù)表中的數(shù)據(jù)一條條插入到索引表當(dāng)中,但是此種方法效率難以接受.考慮到索引表在磁盤中是以SSTable的形式進(jìn)行存儲(chǔ)的,可以實(shí)現(xiàn)一種批量加載的方法,構(gòu)造出索引表數(shù)據(jù)的SSTable.批量加載效率很高,但是難點(diǎn)在于如何收集分布在集群各個(gè)部分的CS上的數(shù)據(jù),也在于如何對(duì)收集的數(shù)據(jù)進(jìn)行排序.3.1將介紹批量加載實(shí)現(xiàn),3.2節(jié)簡(jiǎn)單介紹索引一致性模型.
3.1 基線服務(wù)器上索引的批量加載
3.1.1 批量加載實(shí)現(xiàn)
批量加載的難點(diǎn)在于對(duì)收集的數(shù)據(jù)進(jìn)行排序,為了盡可能避免全表掃描,本文將排序分為局部排序和全局排序兩個(gè)階段.批量加載過程充分利用架構(gòu)特點(diǎn),在集群中的每個(gè)CS上單獨(dú)進(jìn)行,可以避免大量數(shù)據(jù)遷移.同時(shí)使用多線程技術(shù),并行處理數(shù)據(jù)表的不同tablet數(shù)據(jù),加快批量加載流程的速度.
在數(shù)據(jù)表上創(chuàng)建索引表的時(shí)候,必須將數(shù)據(jù)表中已經(jīng)存在的數(shù)據(jù)批量加載到索引表當(dāng)中,之后,索引表才能夠正常提供服務(wù).合并子模塊定期將UPS中的增量數(shù)據(jù)合并到CS中,論文[12]描述了一種具體的合并模塊的工作流程,稱為每日合并模塊,采取排序合并算法進(jìn)行數(shù)據(jù)合并.因?yàn)樵谒饕考虞d過程當(dāng)中,會(huì)阻斷所有的DDL操作,并且索引表批量加載時(shí)必須獲得最新的數(shù)據(jù)表靜態(tài)數(shù)據(jù),所以為了盡量減小索引構(gòu)建過程對(duì)于整個(gè)系統(tǒng)的影響,本文將索引的批量加載安排普通的每日合并流程之后.批量加載主要分為以下四個(gè)階段:第一階段,進(jìn)入批量加載的準(zhǔn)備階段.為了使得索引表能夠獲得最新的數(shù)據(jù),我們?cè)跇?gòu)建索引表之前需要進(jìn)行一次每日合并.因此,合并過程成為批量加載的準(zhǔn)備階段.系統(tǒng)沒有執(zhí)行索引批量加載流程時(shí),所有索引構(gòu)建線程被阻塞,見算法1.

算法1批量加載算法-Schedule輸入:tablet信息或者range信息輸出:索引構(gòu)建信息1.for every thread in each CS do 2.get tablets ranges() 3.if(get nothing) 4.pthread cond wait(&cond,&mutex); 5.else if(get tablets) 6.Call construct local(tablet);//完成數(shù)據(jù)tablet準(zhǔn)備,進(jìn)入局部階段7.else 8.Call construct global(range);//收到Range信息,進(jìn)入全局排序階段9.end if 10.end for
其次,進(jìn)入局部索引構(gòu)建階段.如算法2所示,當(dāng)普通的每日合并完成之后,B開始索引的靜態(tài)數(shù)據(jù)部分的構(gòu)建.當(dāng)CS接收到了RS的創(chuàng)建索引的信號(hào)之后,獲得一個(gè)數(shù)據(jù)表的tablet,對(duì)這個(gè)tablet按索引列進(jìn)行排序,并寫到一個(gè)局部的sstable中.完成以上步驟之后,CS向RS匯報(bào)局部索引sstable的信息.

算法2批量加載算法-局部排序(construct local(type&tablet))輸入:局部階段開始信號(hào)輸入:局部有序SStable文件1.get local index handler//喚醒工作線程2.for each local index handler do 3.create new sstable//用于存儲(chǔ)排好序的SSTable 4.sort.get next row(row)//排序5.Add information into index reporter 6.Calc column checksum for data 7.tablet->add local index sstable//SSTable暫存在數(shù)據(jù)表的tablet上8.if(success) 9.Report information to RS 10.else 11.Push this into local failed list 12.end if 13.end for
第三階段,進(jìn)入全局索引構(gòu)建階段.如算法3所示,RS接收到了CS發(fā)過來的采樣信息之后,將索引列劃分為若干個(gè)range,盡量使得每個(gè)CS上的tablet的數(shù)量相等,以達(dá)到負(fù)載均衡. RS將切分后的range信息發(fā)送給CS.CS根據(jù)這個(gè)range信息互相之間拉取數(shù)據(jù).這個(gè)階段完成后,每個(gè)CS B完成了全局的索引構(gòu)建.最后一個(gè)階段是索引表批量加載完成階段.這個(gè)階段完成復(fù)制全局索引備份,檢查數(shù)據(jù)校驗(yàn)和,修改索引表狀態(tài)為可用.

算法3批量加載算法-全局排序(construct global(type&range))輸入:全局階段開始信號(hào),RS發(fā)送過來的Range輸出:全局有序SSTable文件1.get global index handler 2.for each global index handler do 3.start agent//agent從其他CS或自己上獲取某個(gè)range內(nèi)的數(shù)據(jù)4.execute get data plan 5.root.get next row()//調(diào)用local agent和interactive agent獲取數(shù)據(jù)6.do column checksum 7.construct index tablet info//構(gòu)造索引表的tablet信息8.close sstable//saving sstable in disk 9.if(success) 10.release sstable//釋放局部階段SStable信息11.do data checksum,modify index status 12.report information to RS 13.else 14.Push this into global failed list 15.end if 16.end for
3.1.2 范圍切分算法
整個(gè)批量加載過程中涉及到CS和RS信息的交互以及CS之間的數(shù)據(jù)拉取.每臺(tái)CS在完成索引構(gòu)建局部排序階段之后,進(jìn)行Range信息采樣,并匯報(bào)給RS,采樣信息以等高直方圖的形式記錄.RS根據(jù)采樣信息進(jìn)行Range劃分,決定每個(gè)CS全局排序的范圍.樣本數(shù)的設(shè)計(jì)會(huì)影響Range切分的均衡性,樣本數(shù)越高,Range切分越均衡.但是樣本數(shù)目太多,采樣過于頻繁影響性能,并且網(wǎng)絡(luò)傳輸代價(jià)也會(huì)隨之增大.因此本文實(shí)現(xiàn)將樣本數(shù)定義為tablet的數(shù)目,并且設(shè)置一個(gè)最大值,當(dāng)tablet數(shù)目超過最大值時(shí),樣本數(shù)被設(shè)置為最大值.
在算法4中,max bucket num是預(yù)設(shè)采樣等高直方圖桶的數(shù)目,值為256;tablet num是該數(shù)據(jù)表對(duì)應(yīng)的數(shù)據(jù)分片的數(shù)目,sample num是樣本數(shù).采樣時(shí),每隔N行取出此行的主鍵信息作為Range的End key,N=(tablet總行數(shù)/sample num).每個(gè)CS獨(dú)立完成采樣,并將采樣信息匯報(bào)給RS.RS接收到所有的來自CS的匯報(bào)信息之后將切分Range信息.首先RS將匯報(bào)信息做一個(gè)排序,見算法4的第三行;其次對(duì)Range進(jìn)行切分,算法4的九到十三行描述了RS切分RANGE詳細(xì)過程.

算法4:RS Range切分算法輸入:來自CS的匯報(bào)信息ReportInfo輸出:切分結(jié)果集Res 1.key=decode ReportInfo 2.if all reported is true and decoded successfully 3.sort all range info from ReportInfo//對(duì)匯報(bào)結(jié)果進(jìn)行排序4.end if 5.sample num=min(max bucket num,tablet num)//計(jì)算樣本數(shù)目6.for iter in[SortedReportInfo.begin(),SortedReportInfo.end())do 7.temp range count++ 8.end for 9.range step=temp range count/sample num//RS計(jì)算切分步長(zhǎng)10.divide range count=(temp range count%range step==0)?sample num:sample num+1 11.for(int I=0;I<temp range count;I+=range step)do 12.Res[I].put(key) 13.end for 14.return Res
3.2 索引緩存方式調(diào)整
LSM Tree架構(gòu)下的索引與傳統(tǒng)的索引比較,其讀操作需要一次內(nèi)存訪問和至少一次磁盤訪問,因此速度會(huì)比傳統(tǒng)的索引讀操作慢一些.
在很多應(yīng)用場(chǎng)景下,應(yīng)用程序處理的語(yǔ)句幾乎都是相同,而變化的都是where,set或者values后面的變量的具體數(shù)值.
針對(duì)這種場(chǎng)景,緩存索引查詢的計(jì)劃樹,動(dòng)態(tài)調(diào)整查詢參數(shù)是非常有意義的.實(shí)現(xiàn)時(shí),為每個(gè)索引查詢分配一個(gè)sql id,將<sql id,query plan>以hashmap的形式存儲(chǔ)在內(nèi)存當(dāng)中.相同的sql id可以在內(nèi)存中獲取相同的查詢計(jì)劃,避免了重復(fù)的查詢解析過程.
4 實(shí)驗(yàn)結(jié)果與分析
4.1 實(shí)驗(yàn)環(huán)境
本文在阿里巴巴集團(tuán)開源的分布式數(shù)據(jù)庫(kù)系統(tǒng)OceanBase[13]上實(shí)現(xiàn)了輔助索引功能,以下簡(jiǎn)稱OB.OB是一款增量數(shù)據(jù)和基線數(shù)據(jù)分離的LSM架構(gòu)的分布式數(shù)據(jù)庫(kù)產(chǎn)品,主要是為了解決淘寶網(wǎng)面臨的大規(guī)模數(shù)據(jù)存儲(chǔ)和管理問題.OB具有良好的可擴(kuò)展性,能夠?qū)崿F(xiàn)了數(shù)千億條記錄、數(shù)百TB數(shù)據(jù)上的跨行跨表事務(wù)[14].
本文實(shí)驗(yàn)集群搭建在4臺(tái)服務(wù)器上.每臺(tái)服務(wù)器的硬件環(huán)境如下:64-bit 2.00 GHz 24核Intel(R)Xeon(R)CPU E5-2620,132 GB內(nèi)存,千兆以太網(wǎng),磁盤3.7TB,操作系統(tǒng)CentOS release 6.5(Final).將RS和UPS配置在同一臺(tái)服務(wù)器上,另外三臺(tái)服務(wù)器均配置為MS和CS,數(shù)據(jù)庫(kù)的副本數(shù)目設(shè)為3.
實(shí)驗(yàn)的目的在于驗(yàn)證本文實(shí)現(xiàn)的輔助索引對(duì)于提高查詢速度的帶來的貢獻(xiàn),以及驗(yàn)證本文在索引上所做的一系列優(yōu)化的效果.
4.2 實(shí)驗(yàn)結(jié)果及分析
實(shí)驗(yàn)1使用雅虎的標(biāo)準(zhǔn)測(cè)試工具YCSB(Yahoo!Cloud Serving Benchmark)[15]進(jìn)行測(cè)試,并選擇工作負(fù)載C,這個(gè)工作負(fù)載是100%的讀操作,Query執(zhí)行總次數(shù)為10萬(wàn)次,為了與索引讀返回列數(shù)相同,readallfields設(shè)置為false.本文對(duì)YCSB進(jìn)行了擴(kuò)展,使得YCSB核心負(fù)載集能夠進(jìn)行非主鍵列查詢.為簡(jiǎn)化實(shí)驗(yàn),本文重新定義數(shù)據(jù)生成方式,保證索引列于PRIMARY KEY是一對(duì)一的關(guān)系.實(shí)驗(yàn)采用數(shù)據(jù)集為1000萬(wàn)行,使用YCSB實(shí)現(xiàn)的JDBC數(shù)據(jù)庫(kù)層接口逐行導(dǎo)入.在未添加索引時(shí),利用YCSB對(duì)OB非主鍵進(jìn)行查詢,超出YCSB響應(yīng)時(shí)間限制,未得出實(shí)驗(yàn)數(shù)據(jù).實(shí)驗(yàn)1可以從側(cè)面反映出輔助索引實(shí)現(xiàn)后對(duì)于查詢的性能提升.考慮到索引的具體實(shí)現(xiàn),本文將原表索引查詢與原表主鍵查詢進(jìn)行對(duì)比,結(jié)果如圖4.

圖4 YCSB只讀查詢性能對(duì)比Fig.4Only-read performance using YCSB
可以看到,索引查詢速度基本和主鍵查詢速度一致.兩組實(shí)驗(yàn)分別在80和100個(gè)線程數(shù)時(shí)吞吐率達(dá)到最優(yōu),這是因?yàn)楸疚乃龅膶?shí)驗(yàn)使用YCSB連接到一個(gè)MS上.單臺(tái)MS對(duì)于連接數(shù)目有一定限制,當(dāng)超過這個(gè)限制的時(shí)候,線程在MS發(fā)生沖突,并排隊(duì)等待,性能不會(huì)隨著線程數(shù)目上升.實(shí)驗(yàn)可以得出結(jié)論:索引查詢性能能夠達(dá)到主鍵查詢的性能,而未實(shí)現(xiàn)索引查詢之前,非主鍵列查詢無(wú)法完成.
實(shí)驗(yàn)2測(cè)試使用一張商品表item,主鍵為itemkey,在type屬性上建立索引,count是表中不被索引表覆蓋的一列.數(shù)據(jù)集大小為1 000萬(wàn)行,891MB.測(cè)試中使用SQL如下所示:
Query1:select itemkey from item where type=
Query2:select itemkey from item where type=?
Query3:select count from item where type=
Query4:select count from item where type=?
參數(shù)使用隨機(jī)數(shù)產(chǎn)生,保證一定命中數(shù)據(jù)庫(kù)中的數(shù)據(jù).?表示此版本的數(shù)據(jù)庫(kù)實(shí)現(xiàn)了索引查詢計(jì)劃的緩存.
基于輔助索引的實(shí)現(xiàn)策略,可以將索引查詢分為兩類:回表和不回表,具體是指查詢是否需要從索引表對(duì)應(yīng)的數(shù)據(jù)表中取出數(shù)據(jù).如圖5中所示,NotBack prepared代表的是不回表的查詢并且會(huì)緩存索引查詢執(zhí)行計(jì)劃(Query2),Notback Notprepared代表的是不回表且不會(huì)緩存執(zhí)行計(jì)劃的查詢(Query1),Back prepared代表的是回表且緩存執(zhí)行計(jì)劃的查詢(Query4), Back Notprepared代表的是回表且不會(huì)緩存執(zhí)行計(jì)劃的查詢(Query3).分別比較回表和不回表情況下,緩存索引查詢計(jì)劃對(duì)于性能的提升.回表情況下性能提升了6倍左右,不回表的情況下性能提升在3~7倍之間.

圖5 緩存執(zhí)行計(jì)劃性能對(duì)比Fig.5Execution plan performance
5 結(jié)語(yǔ)
主索引和輔助索引對(duì)于數(shù)據(jù)庫(kù)查詢優(yōu)化有重要的意義.現(xiàn)在絕大多數(shù)流行的NoSQL數(shù)據(jù)庫(kù)一般只支持到主索引,但是越來越多的應(yīng)用要求非排序列上的查詢操作.本文根據(jù)讀寫分離架構(gòu)存儲(chǔ)體系的特點(diǎn)設(shè)計(jì)實(shí)現(xiàn)分布式的二級(jí)索引方案.此方案符合一般的NoSQL架構(gòu),可以很容易在遷移到HBase等其他架構(gòu)類似的系統(tǒng)中.在索引構(gòu)建過程中,遇到各種問題時(shí)故障恢復(fù)工作,以及分布式索引緩存優(yōu)化是本文未來將要考慮的工作.
[1]APACHE ORG.Apache HBase[EB/OL].[2016-07-07].https://hbase.apache.org/.
[2]LAKSHMAN A,MALIK P.Cassandra:A decentralized structured storage system[J].ACM SIGOPS Operating Systems Review,2010,44(2):35-40.
[3]O’NEIL P,CHENG E,GAWLICK D,et al.The log-structured merge-tree(LSM-tree)[J].Acta Informatica, 1996,33(4):351-385.
[4]HUAWEI.Secondary index in HBase[EB/OL].[2016-07-07].https://github.com/Huawei-Hadoop/hindex.[5]CORBETT J C,DEAN J,EPSTEIN M,ET A L.Spanner:Google’s globally distributed database[J].ACM Transactions on Computer Systems(TOCS),2013,31(3):8.
[6]CHEN G,VO H T,WU S,et al.A framework for supporting DBMS-like indexes in the cloud[J].Proceedings of The Vldb Endowment,2011,4(11):702-713.
[7]翁海星,宮學(xué)慶,朱燕超,等.集群環(huán)境下分布式索引的實(shí)現(xiàn)[J].計(jì)算機(jī)應(yīng)用,2016,36(1):1-7.
[8]CHANG F,DEAN J,GHEMAWAT S,et al.Bigtable:A distributed storage system for structured data[J].ACM Transactions on Computer Systems,2008,26(2):4.
[9]TAN W,TATA S,TANG Y,et al.Diff-index:differentiated index in distributed log-structured data stores[C]. Extending Database Technology,2014:700-711.
[10]陽(yáng)振坤.OceanBase關(guān)系數(shù)據(jù)庫(kù)架構(gòu)[J].華東師范大學(xué)學(xué)報(bào)(自然科學(xué)版),2014(5):141-148.
[11]孟必平,王騰蛟,李紅燕,等.分片位圖索引:一種適用于云數(shù)據(jù)管理的輔助索引機(jī)制[J].計(jì)算機(jī)學(xué)報(bào),2012,35(11): 2306-2316.
[12]黃貴,莊明強(qiáng).OceanBase分布式存儲(chǔ)引擎[J].華東師范大學(xué)學(xué)報(bào)(自然科學(xué)版),2014(5):164-172.
[13]ALIBABA INC.OceanBase[Z/OL].[2016-07-07].https://github.com/alibaba/oceanbase/tree/master/oceanbase 0.4.
[14]楊傳輝.大規(guī)模分布式存儲(chǔ)系統(tǒng):原理解析與架構(gòu)實(shí)戰(zhàn)[M].北京:機(jī)械工業(yè)出版社,2013.
[15]COOPER B F,SILBERSTEIN A,TAM E,et al.Benchmarking cloud serving systems with YCSB[C]// Proceedings of the 1st ACM Symposium on Cloud Computing.ACM,2010:143-154.
(責(zé)任編輯:李萬(wàn)會(huì))
Distributed secondary index based on LSM Tree
LONG Fei,WENG Hai-xing,GAO Ming,ZHANG Zhao
(Institute for Data Science and Engineering,East China Normal University, Shanghai200062,China)
In recent years,Log-Structured-Merge Tree has been widely used in NoSQL systems.This is mainly because it has proposed two algorithms:update delayed and batch write,convert random write to batch write,reducing the cost of moving the disk arm therefore the write performance of database has been enhanced greatly.However,the read performance of database has also been affected negatively.The essential difference between LSM Tree and B Tree makes NoSQL not suitable for using B Tree as index structure directly.This paper implements a distributed secondary index based on LSM Tree,and proposes a bulk loading method in this read and write separation architecture.We also do lots of works on the optimization of index query plan to avoid repeatly query parsing IO so that the performance of index read has been greatly improved.
Secondary Index;LSM Tree;NoSQL
TP31
A
10.3969/j.issn.1000-5641.2016.05.005
1000-5641(2016)05-0036-09
2016-05
國(guó)家863計(jì)劃項(xiàng)目(2015AA015307);國(guó)家自然科學(xué)基金(U1401256,61402180, 61402177);CCF-騰訊聯(lián)合研究基金(AGR20150114);上海市自然科學(xué)研究基金(14ZR1412600)
隆飛,男,碩士生,研究方向?yàn)榉植际綌?shù)據(jù)庫(kù).E-mail:451858158@qq.com.
張召,女,副教授,碩士生導(dǎo)師,研究方向?yàn)閿?shù)據(jù)庫(kù).E-mail:zhzhang@sei.ecnu.edu.cn.
猜你喜歡
無(wú)線互聯(lián)科技(2022年15期)2022-11-03 03:19:00
黨員生活(2020年2期)2020-04-17 09:56:30
教育界·中旬(2019年7期)2019-11-24 05:53:39
電腦愛好者(2019年2期)2019-10-30 03:45:31
鐵道通信信號(hào)(2018年10期)2018-12-06 09:34:56
網(wǎng)絡(luò)安全和信息化(2018年2期)2018-11-09 01:16:18
網(wǎng)絡(luò)安全和信息化(2017年3期)2017-03-10 07:45:51
網(wǎng)絡(luò)安全和信息化(2016年8期)2016-11-26 06:42:50
中國(guó)石油企業(yè)(2014年4期)2014-11-30 06:13:06
河南科技(2014年24期)2014-02-27 14:19:25
 華東師范大學(xué)學(xué)報(bào)(自然科學(xué)版)2016年5期
華東師范大學(xué)學(xué)報(bào)(自然科學(xué)版)2016年5期
- 華東師范大學(xué)學(xué)報(bào)(自然科學(xué)版)的其它文章
- 可擴(kuò)展數(shù)據(jù)管理系統(tǒng)中的網(wǎng)絡(luò)請(qǐng)求服務(wù)機(jī)制
- DBugHelper:分布“系統(tǒng)Debug協(xié)助工具
- 面向OceanBase的存儲(chǔ)過程設(shè)計(jì)與實(shí)現(xiàn)
- 非阻塞事務(wù)型實(shí)時(shí)數(shù)據(jù)注入技術(shù)研究與實(shí)現(xiàn)
- 基于Map/Reduce的分布“數(shù)據(jù)排序算法分析
- GraphHP:一個(gè)圖迭代處理的混合平臺(tái)