
Hierarchical Template Matching for Robust Visual Tracking with Severe Occlusions
2012-05-22 01:23:56LizuoJinTiruiWuFengLiuandGangZeng
ZTE Communications 2012年4期
Lizuo Jin ,Tirui Wu ,Feng Liu ,and Gang Zeng
(1.School of Automation,Southeast University,Nanjing 210096,China;
2.ZTE Corporation,Nanjing 210012,China;
3.ZTE Corporation,Chongqing 401121,China)
Abstract To tackle the problem of severe occlusions in visual tracking,we propose a hierarchical template-matching method based on a layered appearance model.This model integrates holistic-and part-region matching in order to locate an object in a coarse-to-fine manner.Furthermore,in order to reduce ambiguity in object localization,only the discriminative parts of an object’s appearance template are chosen for similarity computing with respect to their cornerness measurements.The similarity between parts is computed in a layer-wise manner,and from this,occlusions can be evaluated.When the object is partly occluded,it can be located accurately by matching candidate regions with the appearance template.When it is completely occluded,its location can be predicted from its historical motion information using a Kalman filter.The proposed tracker is tested on several practical image sequences,and the experimental results show that it can consistently provide accurate object location for stable tracking,even for severe occlusions.
Keyw ords visual tracking;hierarchical template matching;layered appearance model;occlusion analysis This work is supported by the Aeronautical Science Foundation of China under Grant 2TELaunches the First PC-Base0115169016.
1 Introduction
O bject tracking,also called visual tracking,involves automatically locating moving objects across successive frames in image sequences.Tracking objects based on their appearance is important in fields such as visualsurveillance,human-computer interaction,robot navigation,and missile guidance.Appearance provides much more comprehensive visual information about objects,and appearance-based object tracking methods have received greater attention in recent decades[1].
However,in real-world visualtracking applications,occlusions are inevitable and usually occur when the view of a moving object is partly or completely blocked by objects such as the static background or other foreground moving objects.When the object is partly or completely occluded,its visual appearance deviates dramatically from its appearance template.Object localization can be very imprecise,and if the appearance template badly damaged due to improper model updating,eventually object tracking is lost[2].
Much research has been down on the heavy impact of occlusions on visual tracking.Adaptive appearance-modeling algorithms deal indirectly with occlusions through statistical analysis[3]-[5].However,the models are susceptible corruption by long-term occlusions and blind updating.In[6]-[9],the object is divided into severalcomponents or patches,and occlusions are evaluated by patch-matching and robust statistics.Using cameras is a good way to handle occlusions,but cameras cannot be applied to many visual-tracking tasks because they require a special setup and come at additional cost[10].In[11],several algorithms are proposed to overcome occlusions in constrained conditions.In[12],occlusions among objects in the context of multiple object tracking are discussed.In[13],occlusions related to specific objects,such as human bodies,in the context of pre-defined model constraints are discussed.In[14],occlusions related to a specific scene using the depth or the motion information are discussed.Afew attempts to manage occlusions and other exceptions have been made based on a spatiotemporal context[14]-[16],and they require many non-trivial observations and tracking of other objects or features outside the target objects.Machine-learning methods such as sparse learning[17],hierarchical feature learning[18],semi-supervised learning[19]-[20]and these can overcome part occlusions to various extents.
In recent years,several methods have been used to deal explicitly with object occlusions.Amixture distribution can be used to model the observed intensity of each pixel where outliers are characterized by the lost component,which has a uniform distribution[21].Some approaches declare outlier pixels by examining whether the measurement error exceeds a predefined threshold,and they work very well only when the statistical properties of the occlusions agree with the
assumptions[22]-[24].A generalalgorithm for detecting and handling occlusions is proposed in[25].The algorithm learns a classifier by observing the likelihood of a few types of occlusion patterns based on the data gathered during the tracking of object with and without occlusions.This is an improvement on several existing tracking algorithms,but because of misclassification,error rate is not low enough.
Occlusions create four basic issues for appearance-based tracking methods[24].The first is how to robustly determine the portion of occlusions;the second is how to accurately locate the object when the situation of occlusions is unknown;the third is how to properly update the appearance model in order to keep tracking the object while preventing damage by outliers;and the fourth is how to reliably detect the reemergence of the object and recapture it after it has been occluded completely for a period of time.To tackle these issues and handle the variations of object appearance caused by occlusions,we propose a hierarchical template-matching method for tracking.This method integrates holistic-and part-region matching in order to locate the object within a search window in a coarse-to-fine manner.
Section 2 describes the hierarchical representation of object appearance.Section 3 contains a brief review of the overall structure of the proposed tracker,and the hierarchical template-matching algorithm is detailed.The algorithm provides the accurately locates the object,even when there are severe occlusions.Section 4 contains experimentalresults and analysis.Section 5 concludes the paper.
2 Hierarchical Representation of Object Appearance
To track an object,we need to locate it first.This can be done in a predicted region far smaller than the whole field of view.This predicted region is usually based on the historical information of the object’s motion and the appearance model of the object,which is adaptively updated.The success of a tracking algorithm depends greatly on the appearance model and the localization method.Some interesting ideas from object classification can be applied to object locating.In severalrecent schemes for object classification,the basic features used for classification are local image fragments,or patches,that depict significant object components and are chosen from training images on the learning stage.The features can be selected from a large pool of candidate image fragments or a set of regions yielded by applying interest operators.On the classification stage,the features are located in the image and are then combined using classification methods such as na?ve Bayesian combination;a probabilistic modelcombining appearance,shape and scale;an ensemble of weak classifiers;and a SVM-based classifier.The features in these methods are non-hierarchical;that is,they are not broken down into simpler,distinct subparts,but are detected one-by-one by comparing the fragment to the image.The similarity between parts can be computed using measures such as normalized cross correlation,affine invariant measure,and SIFT/SURF.Some visual-tracking algorithms use part-based matching techniques to locate the target object from images[6]-[9].
Anumber of classification schemes also use feature hierarchies rather than holistic features.Such schemes are often based on biological modeling and the structure of the primate visual system.Such a system uses a hierarchy of features of increasing complexity,from simple localfeatures in the primary visual cortex to complex shapes and object views in higher cortical areas.In a number of biological models,the architecture of the hierarchy(size,position,shape of features and sub features)is predefined or learnt for different classification tasks.Recent advances in object classification using feature hierarchies have produced promising results on some benchmark datasets[27]-[29].
Representing object appearance using informative components is useful for handling variations in appearance during tracking.However,these components,like the objects themselves,can vary considerably in appearance.Therefore,it is natural to decompose the components into multiple informative subparts.A repeated division process results in a hierarchicalrepresentation of an object with informative parts and subparts in multiple layers.Such hierarchical decomposition can substantially improve object localization.The division process properly classifies objects by learning on a training dataset[27]-[29].However,we apply only regular grids of different sizes to decompose the object into informative parts for balancing the computation and the discrimination capability.Finally,a layered-appearance model is built.The division process is shown in Fig.1.The regular grids applied in the three layers are 1×1,2×2,and 4×4.
We want to use this hierarchical representation to accurately locate the object in a predicted region,not in the whole field of view.Therefore,the localization capability of each part is important and can be checked by the cornerness measure proposed in[26]that was first applied to detect corner features from images and later to choose the informative patches for object tracking.Only those parts with large cornerness measure are accepted as informative features for tracking objects.If we consider a part Iin one layer,we can compute its second-moment matrix M using

where wx,yis the weight,Ixis the horizontalgradient,and Iyis the vertical gradient.If the eigenvalues of M areλ1andλ2,the corner response function R can be used to verify whether it is informative:


▲Figure 1.The layered-appearance model of an object formed by applying regular grids to decompose the components into parts.
whereαis a constant with a value of 0.04 to 0.06.
3 Object Localization by Hierarchical Template Matching
3.1 Overall Structure
The initial target object is specified by manually or automatically selecting a target region,typically covering a rectangular area.The target region is referred to as the region of interest(ROI)and tightly bounds the object to be tracked.Some background pixels might also by included in the ROI during initialization,but this does not matter too much.
We also initialize a validation mask that represents the locations of all informative parts.This mask is a binary matrix with a value of one(where the pixel belongs to the informative parts)or zero otherwise and is built using the method described in section 2.The appearance template reflects the current estimated object appearance and is initialized by sampling pixels from the initial ROIthrough coordinate transformation.The initial occlusion mask is just a duplication of the validation mask,which indicates that no pixel in the template is masked out except the non-informative parts.
Objects are tracked in two operation modes:normaland complete.In normal mode,the target location and ROIare predicted by first using an adaptive-velocity model when each new frame comes in.Then,the approximate target region is obtained by hierarchical template matching.We first analyze the occlusions within the ROIby matching each part in the template and updating the occlusion mask.Then,we perform masked template matching based on the result of occlusion analysis.This rectifies the target location of the object.The result that is output by template matching determines the final ROI,and within this ROI,the occlusion is analyzed again to generate the final occlusion mask.After obtaining the accurate target location and finalocclusion mask,we update the masked template by temporal smoothing.When more than 80%of the target object is occluded,our proposed tracker enters complete occlusion mode,and the location of the target object is predict by a Kalman filter.The reappearance of the target object is reliably detected by the template matching method.Once the end of a complete occlusion is declared,the occlusion mask is reinitialized,and the tracker resumes in normal mode.
3.2 Evaluating the Situation of Occlusions
A layered-appearance model of parts is introduced in section 2 to represent the object,of which,the top layer is the fullobject,the second layer has four non-overlapping parts yield by half dividing the full object at the top layer along the x and y dimension equally,and the third layer has sixteen non-overlapping sub-parts yield by half dividing each part at the second layer in the same manner,each part has four corresponding sub-parts respectively and therefore the object can be described finely more and more.
The similarity between each corresponding part of a candidate object and target object can be measured by the normalized cross-correlation score(NCC).When the NCC is large enough,the parts of the candidate object and target object are taken to be the same.When the NCC is small enough,the parts of the candidate object and target object are taken to be different.When searching for the object at candidate locations,the NCC of the part at the top layer is computed first.If it is high enough,the object is accepted;if it is too low,the object is rejected;otherwise,NCC of the parts in the next layer is computed untilan inference can be confidently made or the lowest layer is reached.After these operations,when no occlusion occurs,the object can be located by computing the NCC in the top layer.When occlusions occur,most regions with a small NCC are rejected in the top layer,and only potential regions with a mid-range NCC are analyzed.Occlusions can be evaluated with the coverage number of parts having a high NCC.Because of the different coverage area of parts in a different layer,the coverage number of parts(CNP)is

where wlis the weight of layer l,and NCCilis the NCC of object part i in layer l.The indication function is I(.),and the predefined threshold isθ.If CNPis smaller than 90%,partial occlusions is acclaimed;if it is very low,for example smaller than 20%,complete occlusions is accepted.Accordingly,a new occlusion mask is generated where the occluded parts are set zero and others are set one.
3.3 Locating the Object
For each image frame,the estimated template is mapped to the frame by coordinate transformationφ(x,α).The type of the transformation is determined by its parameter vectorα.In this paper,only translation is considered;all other types of object motion are regarded as variations in object appearance.The final location of the object in frame n is determined by performing masked template matching with
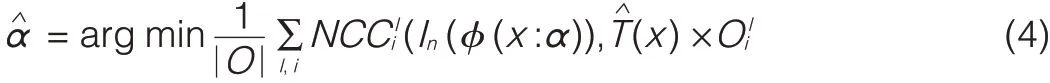
Whereαis the estimated transformation parameter vector,In is frame n,T is the appearance template,l and i represents the part i in layer l,and O is a binary-valued occlusion mask that masks out the occluded template parts.|O|is used to calculate the number of template parts that are not occluded.
In an implementation,αis first computed by fast-searching(using hierarchicaltemplate matching)within a small region predicted by a Kalman filter.At this point,we do not have a reliable occlusion mask yet.If the object is not completely occluded,the finallocation is refined using(4)in a small region aroundαwith the updated occlusion mask.Otherwise,the final location is the one predicted using the Kalman filter.
To maintain tracking even when an object’s appearance varies,we need to adaptively update the appearance template.Because blind updating can cause template drift,only the non-occluded parts should be considered.Therefore,if the object is not completely occluded,masked template updating is performed by applying temporal smoothing,given by
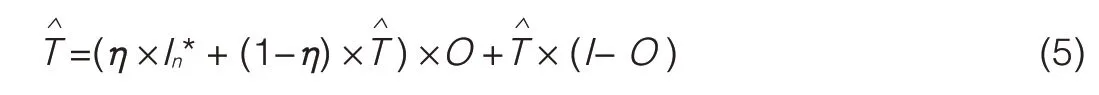
where In*is the best-matched region in frame n;ηis a decaying coefficient;and I is an identity matrix.
4 Experimental Results
To verify performance,the proposed algorithm is tested on an infrared image sequence of a vehicle taken from the video verification of identity(VIVID)dataset,an optical image sequence of an airplane,and an infrared image sequence of a face captured by us in real-world scenarios.The vehicle sequence has heavy occlusions by tree lines;the airplane sequence has part or complete occlusions by background clutters;and the face sequence has severe occlusions by a hand or book.
In Figs.2 and 3,the images in row(a)are the original intensity image,and the white boxes contain the location and size of the target object.The image in row(b)shows the results obtained by applying hierarchical template matching.
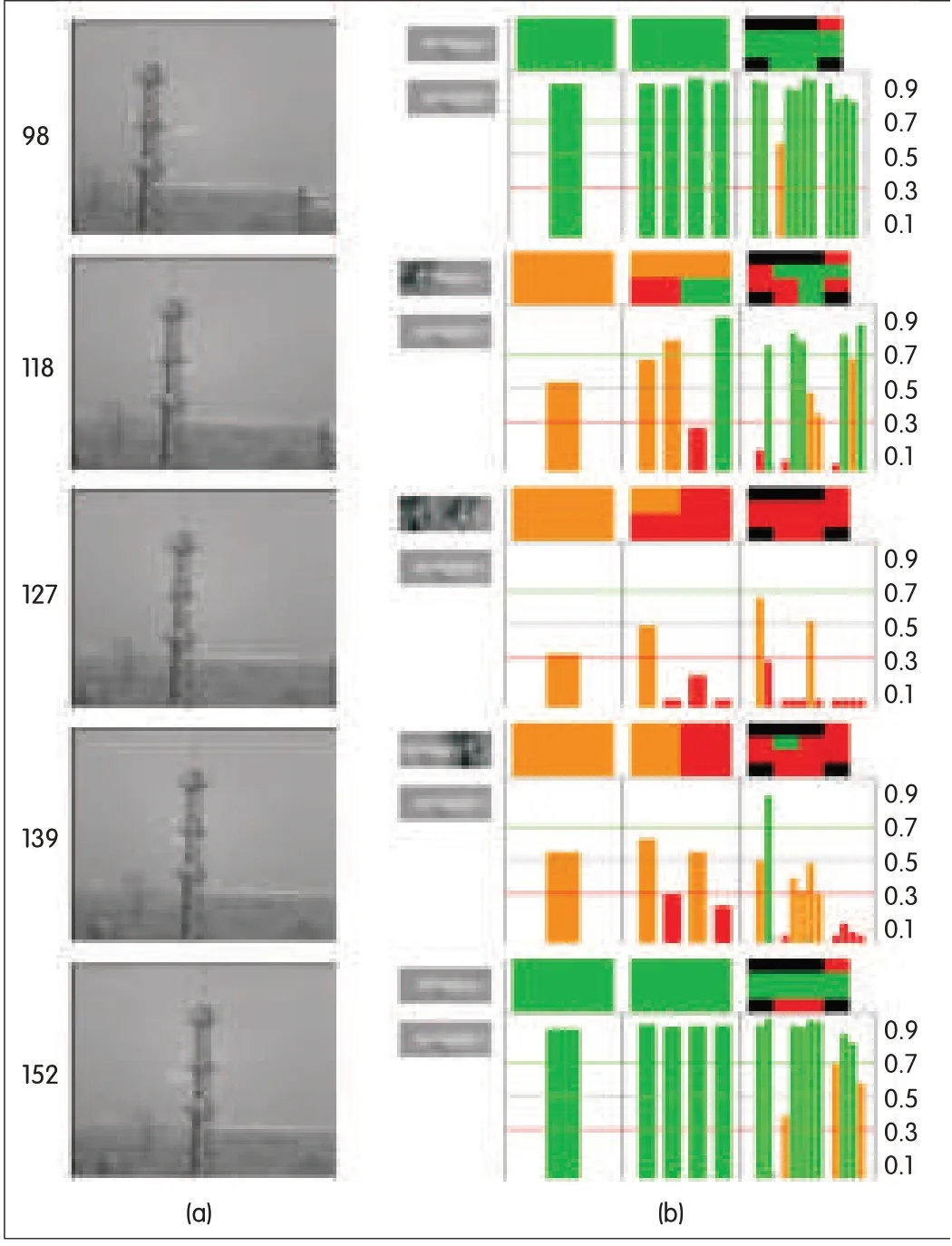
▲Figure 2.Tracking an airplane in opticalimage sequence with severe occlusions.
The small-intensity image at the upper-left of each of the columns in row(b)is taken from the white-box region in the corresponding image of row(a).In fact,it is the best-matched image to the template or the image from the predicted target region.The small-intensity image at the bottom left of each of the columns in row(b)is the appearance template of the object.The three colored boxes at the top of each column show the results of template matching in layers one to three,from left to right respectively.The bars below these show the corresponding NCC values of template matching,and from these we can evaluate the occlusions.The confidence level of an evaluation is shown using different colors:green means high-level;amber means mid-level;red means low-level;and black means non-informative parts.Fig.2 shows the results of tracking an airplane in an optical image sequence with severe occlusions.The frame 98,118,127,139 and 152 show the tracker works very well even when the object is completely occluded.In frame 98 and 152,the NCC is very high in the first-layer matching when the object is not occluded.In frame 118 and 139,NCC is low in the first-layer matching but high in the second-or third-layer matching when the object is partly occluded.In frame 127,NCC is very low,even in the lowest third layer matching when the object is completely occluded.
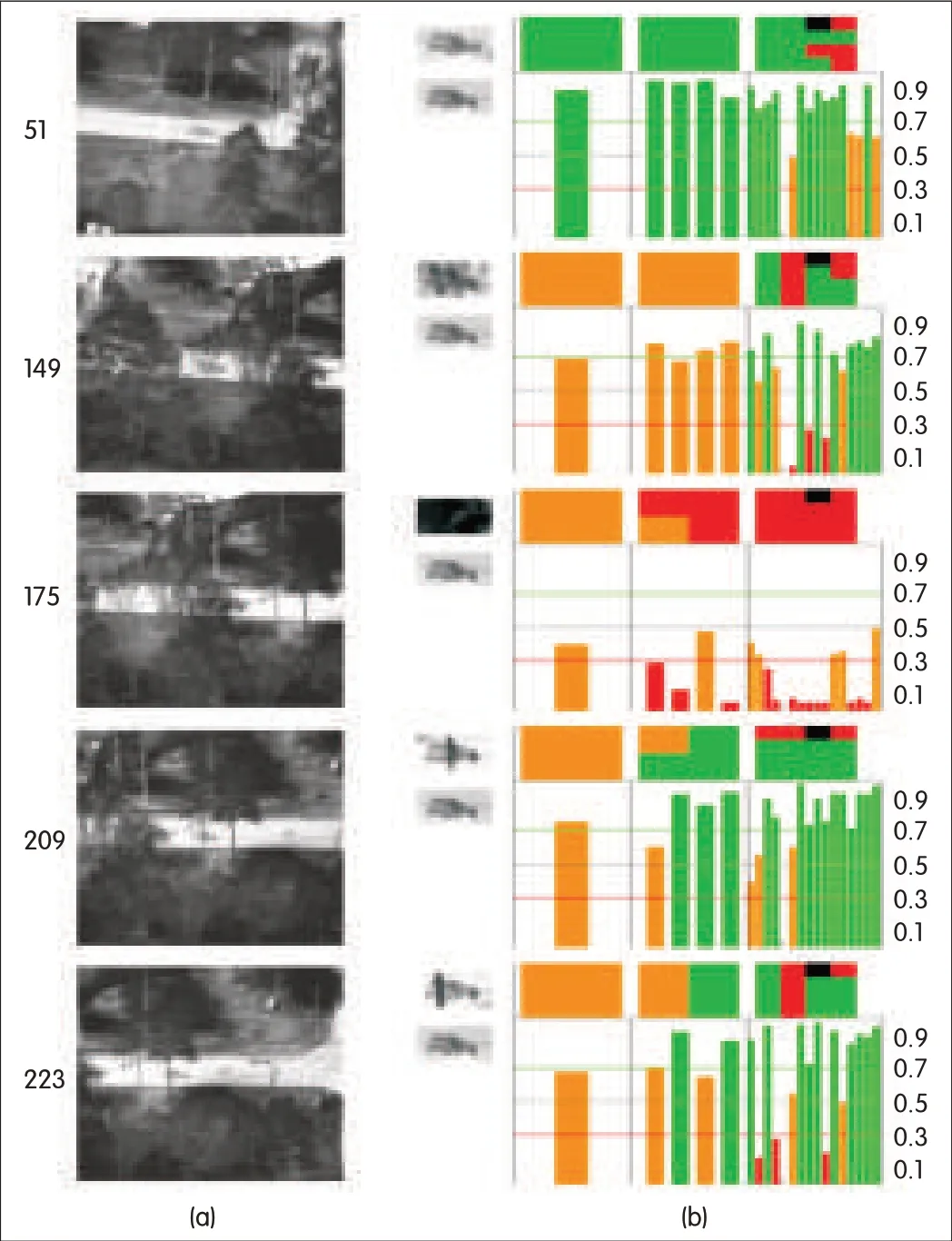
▲Figure 3.Tracking a vehicle in infrared image sequence with severe occlusions.
Fig.3 shows the result of tracking a vehicle in infrared image sequence with severe occlusions.The frame 51,149,175,209 and 223 show that the tracker works very well,even when the object is partly or completely occluded.In frame 51,the NCC is very high in the first-layer matching when the object is not occluded.In frame 149,209 and 139,the NCC is low in the first-layer matching but high in the second-or third-layer matching when the object is partially occluded.In frame 175,the value of NCC is very low,even in the lowest third-layer matching when the object is completely occluded.
Fig.4 shows the coverage number of parts CNPof hierarchical template matching obtained during the tracking of object.The horizontal axis Tshows the index of frames and the vertical axis CNPshows the coverage number of parts CNP.Fig.4(a)is the result of airplane tracking,and Fig.4(b)is the result of vehicle tracking.We can easily determine when the object is partly or completely occluded;for example,in Fig.4(a)from frame 90 to 150,the object is occluded,and in Fig.4(b),from frame 50 to 250,the object is heavily occluded.Although there are some mistakes,we can still take the proper operation to update the appearance template and predict the location of the object using historic information of motion when the object is occluded.This allows for stable,high-quality tracking.
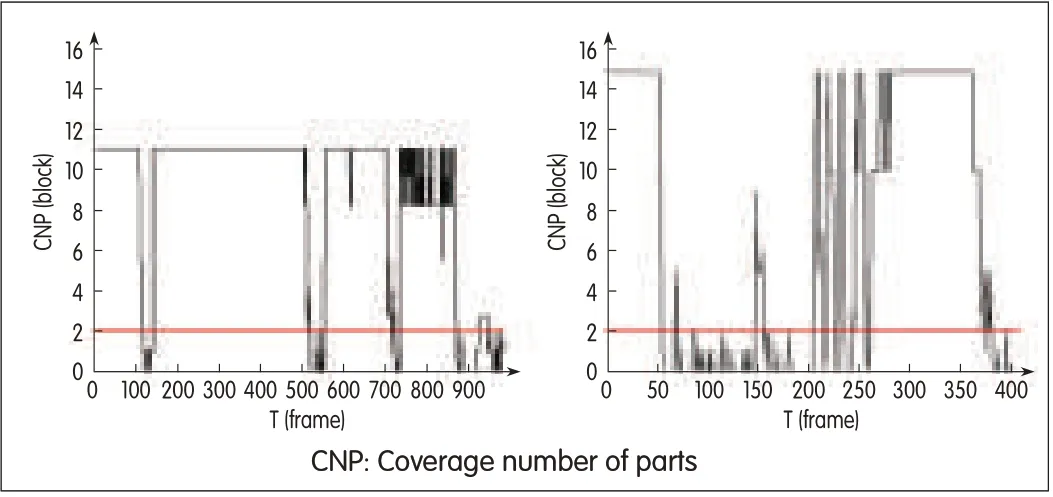
▲Figure 4.Coverage number of parts CNPof hierarchicaltemplate matching obtained during objecttracking.
We developed an active visual tracking system to follow a single moving object,and the proposed tracking algorithm was encoded in an embedded platform in order to locate the object with the core TMS320DM642 processor-a digital signal processor(DSP)chip from TICorporation.Fig.5 shows the result of tracking a face in infrared image sequence with severe occlusions.The sequence was captured by a thermal infrared camera mounted on a gimbal to follow single object.The offset of the location of the tracked object to the center of image yield by our tracking algorithm is fed to a controller to drive the gimbal to follow the object every 40 milliseconds.Thus,it can meet some daily-life requirement of real-time object tracking tasks.In Fig.5,the red boxes show the location of tracked object.Fig.5(a)and(b)shows the location of the tracked face when the size of object changes.Fig.5(c)and(d)shows the location of the tracked face with occlusions.
5 Conclusion
To tackle severe occlusions,a hierarchicaltemplate matching method for object tracking is proposed.The method integrates holistic-and part-region matching in order to locate the object in a coarse-to-fine manner.A layer-appearance modelis introduced to represent the object,and the similarity between a candidate object and the target object is measured by the masked normalized cross-correlation scores of parts in each layer.Occlusions can be easily evaluated using a similarity measure.The proposed method is tested with practical image sequences,and the results show it can consistently provide accurate object location for stable tracking,even for severe occlusions.

▲Figure 5.Tracking a face in infrared image sequence with severe occlusions.
The efficiency of the proposed tracking method comes from two aspects.First,hierarchical template matching can correctly evaluate occlusions and adapt the variations of object appearance due to various types of occlusions.Second,the historicalinformation about motion can be applied to predict the location of object accurately,even when it is completely occluded by clutters.The success of the tracker depends on how to correctly evaluate the situation of occlusions.
Acknowledgement
This work was supported in part by the technique cooperation project of ZTEon Intelligent Video Analysis in 2012.

- ZTE Communications的其它文章
- 2013 IET International Conference on Information and Communications Technologies
- ZTELaunches the First PC-Based CPTfor LTENetworks
- ZTECommunications Guidelines for Authors
- ZTELaunches Innovative Energy-Saving Solution for LTENetworks
- Design and Implementation of ZTE Object Storage System
- Parallel Web Mining System Based on Cloud Platform